Государственные номерные знаки образца 2019 года — журнал За рулем
В следующем году в России появятся номерные знаки доселе невиданных форматов. Введение нового стандарта упростит жизнь как минимум для 8% российских автовладельцев.
Согласно приказу № 555‑ст Росстандарта с 1 января 2019 года вступает в действие новый ГОСТ Р 50577–2018 «Знаки государственные регистрационные транспортных средств. Типы и основные размеры. Технические требования» взамен уже изрядно потрепанного временем ГОСТа образца 1993 года. В этом документе, как оказалось, содержится много интересного. В частности, появится целая россыпь номерных знаков необычного формата, сделанных в угоду владельцам иностранной техники. И не только!
Мытарства
Больше — не всегда лучше. Это вам скажет любой байкер, которому хоть раз приходилось крепить отечественный госномер на мотоцикл иностранного производства. На двухколесных иномарках в большинстве случаев площадка под номер рассчитана на табличку куда меньшего размера, нежели выдают в МРЭО. Сверлить номерá нельзя, даже если очень хочется. Приходится изобретать переходники и заниматься прочим техническим творчеством, дабы присобачить «жестянку» на байк. При этом в известной степени страдает эстетика, что для мотоциклистов особенно больно.
Сверлить номерá нельзя, даже если очень хочется. Приходится изобретать переходники и заниматься прочим техническим творчеством, дабы присобачить «жестянку» на байк. При этом в известной степени страдает эстетика, что для мотоциклистов особенно больно.
Схожие трудности испытывают владельцы автомобилей, привезенных из Америки или Японии: в этих странах исторически используются госномера «более квадратной» формы, а посему наши родные таблички европейского стандарта (520×112 мм) на штатное место иногда не удается водрузить вовсе. Переходник тоже не панацея: установленный госномер может перекрыть заднюю оптику, не говоря уже о том, что еще придется как-то «колхозить» для него подсветку.
Столь крупных табличек, как на этой Хонде, с нового года больше не будет: все мотономера переходят на уменьшенный формат. Однако размер новых табличек всё же будет немного отличаться от японских и американских стандартов.Столь крупных табличек, как на этой Хонде, с нового года больше не будет: все мотономера переходят на уменьшенный формат. Однако размер новых табличек всё же будет немного отличаться от японских и американских стандартов.
Однако размер новых табличек всё же будет немного отличаться от японских и американских стандартов.
Всё меняется
Материалы по теме
Впереди горемычных ждет новая, более удобная эра. Начнем с владельцев «праворуких» япономарок и американомобилей. Возрадуйтесь, господа, теперь вы сможете при регистрации получить табличку, которая имеет все шансы вписаться в штатное место для номера — речь идет о «жестянках», которые устанавливаются на автомобиль сзади. Новый стандарт подразумевает знак размером 290×170 мм — по идее, он как раз должен подойти по параметрам серому импорту. Причем с запасом, поскольку и у «японцев», и у «американцев» размеры номерных табличек даже немного крупнее новых российских: 330×165 мм и 305×160 мм соответственно. Номерá (то есть собственно набор букв и цифр) транспортным средствам будут присваивать в ГИБДД, а изготовление «железок» доверят сертифицированным организациям — тем, что сейчас имеют право изготавливать дубликаты утраченных знаков.
Мотоциклисты тоже не остались в стороне от реформы. Для них приготовили знаки уменьшенного размера 190×145 мм (прежде — 245×160 мм). Для сравнения: в Японии на мото вешают таблички 230×125 мм, в Штатах — 180×100 мм. В любом случае станет явно лучше, чем было.
К слову, выбирать «жестянку» подходящего размера не придется: в новом ГОСТе от больших госномеров старого формата не осталось и следа. Но мы ведь не будем лить по ним слезы, верно?
Многие владельцы «американцев» всячески импровизируют, пытаясь приладить «евростандартные» номера на свои машины. Далеко не всегда удается сделать это элегантно.Многие владельцы «американцев» всячески импровизируют, пытаясь приладить «евростандартные» номера на свои машины. Далеко не всегда удается сделать это элегантно.
Тоже транспорт
В совсем еще свежем (можно даже сказать, немного сыром) ГОСТе отметились и другие знаки. Например, госномерá для «внедорожных транспортных средств, не предназначенных для движения по автомобильным дорогам общего пользования», - под такой техникой подразумеваются главным образом квадроциклы (ATV) и снегоходы, которые с точки зрения чиновников являются скорее тракторами и посему проходят регистрацию в Гостехнадзоре. Регзнаки на них тоже будут уменьшенными — по аналогии с мотоциклетными. От последних они должны отличаться структурой расположения букв и цифр. То же касается и спецзнаков для мопедов, которые отныне также предусмотрены новым ГОСТом. Правда, чтó следует считать мопедом, пока не до конца ясно: то ли речь идет только о макси-скутерах с достаточно кубатурными моторами (более 50 см³), то ли под одну гребенку причешут вообще всю мототехнику, не подпадающую под определение «мотоцикл». Подождем — узнаем.
Регзнаки на них тоже будут уменьшенными — по аналогии с мотоциклетными. От последних они должны отличаться структурой расположения букв и цифр. То же касается и спецзнаков для мопедов, которые отныне также предусмотрены новым ГОСТом. Правда, чтó следует считать мопедом, пока не до конца ясно: то ли речь идет только о макси-скутерах с достаточно кубатурными моторами (более 50 см³), то ли под одну гребенку причешут вообще всю мототехнику, не подпадающую под определение «мотоцикл». Подождем — узнаем.
Материалы по теме
Нет и четкого понимания того, кому адресованы еще две категории госномеров, которыми разжился ГОСТ 2018 года. В отдельную группу выделены «классические (ретро) и спортивные транспортные средства». По смыслу в целом понятно, о чем идет речь. Но с точки зрения Правил дорожного движения — да и вообще законов Российской Федерации — таких транспортных средств у нас в природе как бы не существует. Всё, что незамутненным разумом может быть истолковано как олдтаймер, по закону является обычным автомобилем.
Можно лишь предполагать, зачем такие спецномера нужны в перспективе и в принципе. Возможно, для классических автомобилей сделают какие-либо поблажки в плане норм выброса (скажем, разрешат въезд в зоны с лимитом по экологическому классу) — но при этом придумают иные ограничения. Что же касается спортивных машин, то здесь речь может идти о допуске «спортинвентаря» на дороги общего пользования в рамках отдельно взятых соревнований — ралли-рейдов, например.
И всё же в целом введение нового ГОСТа можно только приветствовать: по всему выходит, что польза от него явно будет, а вреда вроде как и нет. С наступающим вас!
| Антон Шапарин, вице-президент Национального автомобильного союза Антон Шапарин, вице-президент Национального автомобильного союза МнениеВведение нового стандарта упростит жизнь как минимум для 8% российских автовладельцев, эксплуатирующих праворульные автомобили и машины, импортированные из США. |
 Устраняется и правовой пробел: серьезно доработанные спортивные автомобили зачастую нельзя зарегистрировать в ГИБДД, так как они могут не соответствовать нормам ТР ТС 018/2011, а без регистрации их нельзя эксплуатировать в РФ. Теперь предстоит разработать критерии выдачи для них спортивных номеров. А вот новые номера для классических автомобилей — это заметный риск, так как владельцы олдтаймеров могут столкнуться с ограничениями по эксплуатации своих машин. Правила выдачи таких номеров также пока не определены.
Устраняется и правовой пробел: серьезно доработанные спортивные автомобили зачастую нельзя зарегистрировать в ГИБДД, так как они могут не соответствовать нормам ТР ТС 018/2011, а без регистрации их нельзя эксплуатировать в РФ. Теперь предстоит разработать критерии выдачи для них спортивных номеров. А вот новые номера для классических автомобилей — это заметный риск, так как владельцы олдтаймеров могут столкнуться с ограничениями по эксплуатации своих машин. Правила выдачи таких номеров также пока не определены.Фото: Артем Геодакян/ТАСС
Номера нового формата — уже скоро!В следующем году в России появятся номерные знаки доселе невиданных форматов. Введение нового стандарта упростит жизнь как минимум для 8% российских автовладельцев.
Номера нового формата — уже скоро!Как получить номера нового образца на иномарки?
 Новый ГОСТ Р 50577-2018 на автомобильные, мотоциклетные и тракторные номерные знаки принят без малого два года назад. Однако вступление его в силу уже несколько раз переносили по просьбам ГИБДД и Минсельхоза РФ, чтобы до этого момента израсходовать уже изготовленные номерные знаки. В настоящее время приказом Росстандарта от 23.07.2019 №423-ст дата введения в действия ГОСТ Р 50577-2018 назначена на 04 августа 2020 года.
Новый ГОСТ Р 50577-2018 на автомобильные, мотоциклетные и тракторные номерные знаки принят без малого два года назад. Однако вступление его в силу уже несколько раз переносили по просьбам ГИБДД и Минсельхоза РФ, чтобы до этого момента израсходовать уже изготовленные номерные знаки. В настоящее время приказом Росстандарта от 23.07.2019 №423-ст дата введения в действия ГОСТ Р 50577-2018 назначена на 04 августа 2020 года.В нынешний «переходный» период владельцы автомототранспорта могут получить при регистрации как традиционный задний номерной знак, так и новый двухрядный («квадратный»). Номера подобного формата используют в Японии, США и некоторых других государствах. До настоящего времени для установки на машины из этих стран российских номеров водители их подгибали (что запрещено) или использовали специальные переходники-проставки.
Как сообщили ИА «1-Line» в ГИБДД, с 1 января наступившего года автовладельцы могут заказать задний номерной знак (передний для всех вариантов остаётся «прямоугольным» традиционного формата), для которого переходник не потребуется.
«Нужно разделять понятия. Знак – это пластина, которую автовладелец крепит на свою машину, а номер – это буквенно-цифровое сочетание на этом знаке, которое записано в Свидетельстве о регистрации транспортного средства (СТС), —
Надо сказать, что этот «раздельный» путь получения госномеров чуть длиннее прежнего, когда автовладельцы получали номерные знаки вместе с регистрационными документами. Впрочем, он касается именно тех, кому нужны знаки нового образца, обычные же можно получить, как и раньше, вместе с документами.
Немаловажный нюанс – регистрировать автомобиль можно только по месту своего жительства. Граждане, не прописанные в Красноярском крае, номерные знаки с индексом региона 24 или 124 не получат. В Красноярске в РЭО ГИБДД такому человеку выдадут СТС, но присвоят номер с индексом его региона.
И ещё одно уточнение. Владельцы уже зарегистрированных иномарок также могут заказать своему авто задний номерной знак нового образца. Никаких регистрационных действий для этого не требуется, поскольку буквенно-цифровые сочетания госномера одинаковы для любого формата.
ГОСТ Р 50577-2018 также предусматривает особые номера для классических (ретро) и спортивных автомобилей и мотоциклов. Однако пока такие номера в Красноярске не выдают и не изготавливают.
Номера нового образца
Toyota Mark II Сугроб «Благовещенский» › Бортжурнал › #9 Актуальная и полная информация по ГОСТу 50577-2018, законность и варианты установки «квадратного» номера типа 1А.

Всех приветствую!
В последнюю пару недель не утихают споры касательно возможности/законности установки новых квадратных номеров.
Напоминаю, что с 4 августа 2019 в силу должен был вступить ГОСТ 50577-2018, в котором прописана возможность установки заднего номерного знака на автомобиль с нестандартным местом крепления регистрационного знака типа 1А.
Полный размер
Регистрационный знак типа 1А
По итогу ввод в действие ГОСТа 50577-2018 был перенесён на 4 августа 2020-го, но с правом его досрочного применения. Иными словами выдача данных знаков в ГИБДД станет возможна не раньше августа 2020, но никто не запрещает вам изготовить данный номер в организациях, имеющих на это разрешение уже сегодня, так я понимал формулировку «право досрочного применения».
Но у нас как всегда, уверенности не было. Мной был сделан запрос в УМВД РФ по Амурской области касательно возможности и законности установки данных типов номерных знаков.
Ответ ниже на скрине:

Теперь можно официально, законно ставить такие номера не боясь штрафов и тд. Во всяком случае в нашей области. В Хабаровском крае люди получают аналогичные ответы (понятно что это всё шаблонные ответы, я думаю таких запросов в последнее время они получили множество). Но в некоторых регионах нашей обширной страны ничего об этом не знают и ставить пока не разрешают, всё на свой страх и риск, либо делайте аналогичный запрос в своё региональное управление МВД и возите официальный ответ с собой.
Теперь касательно организаций, которые имею право на изготовление таких номеров-дубликатов:
2) Помимо того, что организация должна быть в официальном списке, у неё должно быть разрешение или так называемое свидетельство на изготовление данного типа номерных знаков. Если все есть, можно смело заказывать.

3) На самом номере, изготовленном по ГОСТу должны быть нанесены голограммы+с обратной стороны уникальная гравировка кода завода-изготовителя.
Полный размер
Мой ГОСТовский номер.
Варианты установки. Наш номер имеет размеры 290х170, японский 330×170, американский 305х155.
Как видим ни одна рамка нам не подойдёт, т.к. наш ГОСТ отталкивался от ещё советского аналогичного ГОСТа. Собственно у вас пять вариантов установки:
1) Покупаем японскую рамку и начинаем её кромсать/подрезать/склеивать/впихивать. Хороший отчёт у Gipsy22, выглядит отлично. www.drive2.ru/l/537912425463153289/
2) Скотч 3М никто не отменял, только нужен оригинал, а то потеряете).
3) Заказать номер под наш ГОСТ, но по японскому размеру и спокойно вставить его в японскую рамку, есть у genyi434, www.drive2.ru/l/538460257131693120/ На свой страх и риск, номер визуально шире, смотрится отлично, но всё зависит от внимательности сотрудника ГИБДД, наличия у него линейки и желания найти у вас нарушение)
4) Сделать отверстия в номере под японские крепления, т. е повесить без рамки. Вариант подойдёт не всем авто, на некоторых моделях останутся небольшие дыры по бокам, потому что японский номер шире. Кстати некоторые организации-изготовители уже сразу предусмотрительно штампуют такие варианты.
е повесить без рамки. Вариант подойдёт не всем авто, на некоторых моделях останутся небольшие дыры по бокам, потому что японский номер шире. Кстати некоторые организации-изготовители уже сразу предусмотрительно штампуют такие варианты.
5) Ну или наконец самый логичный вариант — просто дождаться когда появятся рамки именно под наш типоразмер номера. Сейчас таких я не встречал, хотя через пару недель всё изменится, китайцы наклепают рамок на всю страну).
Я решил остановиться на 4 варианте, т.к скотч потом хрен отдерёшь да и давненько хотел избавиться от всяких рамок. Самое главное, что ГОСТ разрешает сверление отверстий. По ГОСТу так же обязательно соблюдения условий сверловки: не более 4 отверстий на знаке (только для квадратного типа) диаметром не более 7 миллиметров! Винты крепления должны быть светлыми или цвета фона.
Использовал для этого трафарет (спасибо создателю).
Полный размер
Трафарет под японские крепления.
umat.ru/will/gostplatejp.
 pdf ссылка на трафарет.
pdf ссылка на трафарет.
Распечатал, приложил трафарет:
Полный размер
Примерка
Получил точки:
Полный размер
Места сверления.
БУДЬТЕ ОСТОРОЖНЫ С ТРАФАРЕТОМ! Небольшое несоответствие и дырки у вас не совпадут, измеряйте тщательно!
Отверстия делал 6 мм сверлом по металлу. Использовал стандартный крепёжный набор с белыми катафотами, с обратной стороны подложил пару шайб и притянул гайками.
Так же, чтобы номер не «играл» и не царапал кузов был куплен кусочек резинового самоклеящегося уплотнителя (продаётся в любом строительном магазине).
Полный размер
Уплотнитель
Наклеил две полоски сверху и снизу. Теперь номер ничего не царапает и сидит идеально.
Уплотнитель.
Вот что получилось на авто. Смотрится непривычно. Не всем нравится, но на вкус и цвет…
Полный размер
Новый номер.
Полный размер
Новый номер.
Новый номер ставился с целью возможности внедрения камеры заднего вида вместо одного из штатных плафонов подсветки, с возможностью сохранения этой подсветки, старый номер из за рамки не давал возможности этого сделать. О камере расскажу позднее. Дырявить накладку не хотел, рестайл уже с заводским отверстием под камеру мне не нравится. Плюс появилась мало полезная, но всё таки возможность открывать багажник с ключа, ранее опять таки рамка старого номера не давала этого сделать.
О камере расскажу позднее. Дырявить накладку не хотел, рестайл уже с заводским отверстием под камеру мне не нравится. Плюс появилась мало полезная, но всё таки возможность открывать багажник с ключа, ранее опять таки рамка старого номера не давала этого сделать.
P.S. Да и не особо надейтесь — камеры уже настроены на новые номера, фотографии уже приходят «счастливым» нарушителям). Вопрос установки такого же номера на переднюю часть автомобиля остаётся открытым. Пока, к сожалению, по новому ГОСТУ этого делать нельзя. Как всегда рад оценкам/комментариям/критике/вопросам/замечаниям. Спасибо за внимание!
Кому требуются такие номера, чтобы именно по ГОСТу, обращайтесь в личку.
www.drive2.ru
Особенности установки «квадратных» номеров — Toyota Will VS, 1.8 л., 2002 года на DRIVE2
Данные на 5 августа 2019 года :
Появился скрин приказа Росстандарта ( в комментах есть фото приказа)
Появились свидетельства от МВД на право изготовления квадратных номеров по новому ГОСТу ( фото есть ниже) . Появились официальные ответы МВД гражданам с разъяснением ситуации по новым номерам ( скрин документа в комментариях) Есть официальный ответ МВД по этому поводу, есть, наконец то видео разъяснение от МВД. Это юридически, практически и фактически однозначно дает право владельцам автомобилей ставить номера по новому ГОСТу.
Появились официальные ответы МВД гражданам с разъяснением ситуации по новым номерам ( скрин документа в комментариях) Есть официальный ответ МВД по этому поводу, есть, наконец то видео разъяснение от МВД. Это юридически, практически и фактически однозначно дает право владельцам автомобилей ставить номера по новому ГОСТу.
Срок действия ГОСТа перенесли на год, то есть до августа 2020 года, но ниже в приказе внесли строчку:
«С правом досрочного применения»
А теперь разбираем значение этой строки:
Есть такой ГОСТ, который регулирует все аспекты ГОСТов:
ГОСТ Р 1.2-2016 Стандартизация в Российской Федерации. Стандарты национальные Российской Федерации. Правила разработки, утверждения, обновления, внесения поправок, приостановки действия и отмены (с Поправкой)
Там есть абзац про эту строчку:
«…В обоснованных случаях при установлении даты введения национального стандарта в действие пользователям может быть предоставлено право его досрочного применения…»
Короче, поступили хитро, применив этот пункт. Согласно приказа фактически действуют оба ГОСТа в течении года. То есть, приказ не отменяет старый гост, так как дата введения нового госта перенесена на год приказом, но при этом в этом же приказе разрешается использовать новый гост. То есть все пользователи вправе использовать и новый ГОСТ.
Согласно приказа фактически действуют оба ГОСТа в течении года. То есть, приказ не отменяет старый гост, так как дата введения нового госта перенесена на год приказом, но при этом в этом же приказе разрешается использовать новый гост. То есть все пользователи вправе использовать и новый ГОСТ.
Написанное выше уже ушло в историю, так как 19 год уже прошел.
Как простому покупателю узнать «законны ли квадратные номера»?:
Пользователями ГОСТа считаются все его участники. То есть:
МВД — согласно ГОСТа через Гибдд выдает, а точнее присваивает номера и следит за их правильным использованием. Оно наказывает граждан за несоответствие ГОСТу номеров, их отсутствие, за грязные номера, за не читаемые, наличие бумажек, штрафов и долгов и т.д. Помимо этого оно доверяет изготовление дубликатов, оригиналов номеров «печатникам». Факт доверия МВД выглядит в виде свидетельства на право заниматься производством и выдачей специальной продукции гражданам в виде номерных знаков.
«Печатники» — это конторы (ИП и ООО), которые выдают номера. Это могут быть как и сами производители, так и посредники. Официальные автомобильные номера эти конторы выдают на основании лицензии, а точнее свидетельства от МВД. В свидетельстве прописаны типы номеров (квадратный, это ТИП 1А), название ГОСТа ( должен быть ГОСТ Р 50577-2018), и откуда номера ( собственное производство или покупают у какого либо ООО) И, согласно новым законам в мрэо гибдд больше выдавать номера в обязательном порядке не будут. Будут присваивать номер в своих базах, при регистрации выдадут птс и стс и иди сам покупай себе номер. Тем более квадратный. Оплата пошлины в этом случае меньше на стоимость этих самых номерных знаков.
Это могут быть как и сами производители, так и посредники. Официальные автомобильные номера эти конторы выдают на основании лицензии, а точнее свидетельства от МВД. В свидетельстве прописаны типы номеров (квадратный, это ТИП 1А), название ГОСТа ( должен быть ГОСТ Р 50577-2018), и откуда номера ( собственное производство или покупают у какого либо ООО) И, согласно новым законам в мрэо гибдд больше выдавать номера в обязательном порядке не будут. Будут присваивать номер в своих базах, при регистрации выдадут птс и стс и иди сам покупай себе номер. Тем более квадратный. Оплата пошлины в этом случае меньше на стоимость этих самых номерных знаков.
«Граждане» — имеют право приобрести эти номера у «печатников». Для получения они дают деньги, документы (к примеру СТС и паспорт) и получают номера. При этом покупатель подтверждает себе законность получения номера проверив это самое свидетельство. Если продавец клянется, что номера по ГОСТу, а свидетельства нет — номера сувенирные или это простой перекупщик. Если, согласно новому ГОСТу на обратной стороне номерного знака должна быть лазерная маркировка, а ее нет, то номера не по новому ГОСТу. Начиная с 20 года, когда новый ГОСТ вступил в полную силу, большинство конторок, которые находятся в регионах и городках, рекламой которых завалены все поисковики, при звонках к ним несут чушь и вешают лапшу. Или завышают необоснованно цену, или под видом номеров по новому ГОСТу впаривают «сувенирные» номера, без лазерной маркировки или еще что либо на уши вешают. Век их заканчивается — а деньги нужны, вот и крутится, кто как может. Скоро на рынке останутся только крупные игроки и их представители.
Если, согласно новому ГОСТу на обратной стороне номерного знака должна быть лазерная маркировка, а ее нет, то номера не по новому ГОСТу. Начиная с 20 года, когда новый ГОСТ вступил в полную силу, большинство конторок, которые находятся в регионах и городках, рекламой которых завалены все поисковики, при звонках к ним несут чушь и вешают лапшу. Или завышают необоснованно цену, или под видом номеров по новому ГОСТу впаривают «сувенирные» номера, без лазерной маркировки или еще что либо на уши вешают. Век их заканчивается — а деньги нужны, вот и крутится, кто как может. Скоро на рынке останутся только крупные игроки и их представители.
Пример наличия лицензий у ООО» ЗНАК», крупнейшего производителя:
znak.ru/o_kompanii/nashi_svidetelstva/
Проверить, является ли производитель законным можно на сайте ГИБДД, вбивая нужный регион:
xn--90adear.xn--p1ai/r/50/num/
Вот такое свидетельство должно быть у производителя, дающее законное право выдавать квадратные номера типа 1А по новому ГОСТу ( мало кто еще их вывесил на свои сайты, мало кто их еще получил):
Ссылка на официальный статус ГОСТа:
protect. gost.ru/document1…ar=2018&search=&id=231380
gost.ru/document1…ar=2018&search=&id=231380
На момент написания там виден статус «ПРИНЯТ» (нужен «ДЕЙСТВУЕТ»), видна прошлогодняя правка о переносе срока ввода.
Кому можно вешать такие номера:
Только на те автомобили, у которых нестандартное крепление номера. То есть, если захотелось поставить квадрат на европейца, то накажут, если решат докопаться. Если машина «американец» но подномерник широкий и высокий, и есть две лампы подсветки номера и они разнесены — квадрат вешать нельзя. Можно сказать, что такое место не «не стандартное» а скорее универсальное, и под квадраты и под плоские номера. Если подномерное место широкое и высокое, но лампа подсветки штатно одна по центру и рассчитана на квадратный номер — можно и даже нужно вешать, что бы соответствовать ГОСТу по условию читаемости ночью. Если «плоский» номер тупо не лезет в место — конечно ставить только квадрат.
Ставить номерные знаки можно только назад! Это строго регламентировано ГОСТом:
Приложение «Ж» > примечания (страница 32):
Пункт 1 : » На транспортных средствах с нестандартным местом крепления регистрационных знаков допускается установка заднего регистрационного знака типа 1А вместо регистрационного знака типа 1″
Хоть, судя по отзывам, гайцы не наказывают за квадратный номерной знак спереди, а лишь максимум делают предупреждение, но квадрат спереди по закону не по госту однозначно. Вот пример запроса:
Вот пример запроса:
Ну и для справки по рамкам, размеры знаков у соседей:
280х200 Беларусь
280×202 Казахстан
300х150 Украина
288х206 Россия трактор
290х170 черный советский номер — вот откуда слизали размер!
запись 2 февраля 2019 года, для истории, пропускаем, кому это уже не интересно. В самом низу есть только шаблоны для распечатки дырок крепления. Вторая часть, про штрафы, лазерную маркировку, виды знаков и т.д. уже тут : www.drive2.ru/l/540337398358213242/
Все наверное уже знают, что с 19 года планировалось ввести автомобильные номерные знаки нестандартного размера, а точнее ввести номерные знаки, под японский и американский квадратный размер. Конечно знают те, кого это касается, владельцев «японцев» и «американцев» и отчасти советской классики. Особенно мотоциклисты, их номерные знаки по отношению к размеру мотоцикла просто громадные, конено лучше, когда так:
Были новости во второй половине 18 года про эту тему, потом перед новым годом была новость, что ГИБДД не успевает, что перенесли всю канитель на август этого года. Начиная с начала января 19 года начали появляться записи в бортовиках про установку знаков «по новому госту», которые носили явно характер «я первый- зацени», а в комментариях сразу шли дебаты, что за установку этих номеров будет от «ничего не будет» до «расстрела на месте» по всей строгости закона.
Начиная с начала января 19 года начали появляться записи в бортовиках про установку знаков «по новому госту», которые носили явно характер «я первый- зацени», а в комментариях сразу шли дебаты, что за установку этих номеров будет от «ничего не будет» до «расстрела на месте» по всей строгости закона.
По этому сначала юридический аспект:
1. — ГОСТ действительно введен в реестр и принят и даже введен в действие с 01.01.2019. Это ГОСТ Р 50577-2018.
2. — Хоть ГОСТ и введен но это не говорит о том, что он активен. Открываем «Гарант» и ищем по этой теме. Там видно, что старый ГОСТ ГОСТ Р 50577-93 имеет статус «Документ утратил силу или отменен», есть ПРИКАЗ от 4 сентября 2018 г. N 555-ст о введении нового ГОСТа с 01.01.19 и есть дословно » Приказом Росстандарта от 18 декабря 2018 г. N 1131-ст дата введения ГОСТ Р 50577-2018 перенесена с 1 января 2019 г. на 4 августа 2019 г.» То есть, ГОСТ ввели и перенесли на 4 августа, то есть:
3. До 4 августа юридически ездить с номерами по новому ГОСТу нельзя! Приказ сильнее ГОСТа. Колюзия в том, что гост утвердили позже, чем его перенесли: То есть перенесли и утвердили со старым сроком. То есть ситуация из жизни такая:
Стой здесь — иди сюда!
4. Кому можно «заквадратится»?
Всем «гражданским» авто, кроме желтых номеров и только сзади.
«Ожидательный» аспект:
Была информация, что автомобильные номера по новому ГОСТу будут маркировать ( можно сравнить с акцизками на табак и алкоголь — из той же оперы) как это будет выглядеть реально пока неизвестно. В госте описано, что код маркировки содержит 12 символов, имеет высоту 5мм и расположен в нижнем левом углу с обратной стороны знака. Наносится этот код лазером. Если номер дубликат, то первый символ буква «Д». Все знаки сейчас идут без лазерной маркировки. Эта маркировка имеет чисто учетный смысл, ибо любой человек имеющий лазерный гравер сумеет эту маркировку клонировать. Так же как и в старом госте указано наличие штампа имени производителя на обр
www.drive2.ru
«Квадратные» номера разрешили устанавливать на иномарки — Рамблер/авто
Новый ГОСТ разрешает устанавливать госномера нового формата с августа 2019. Об этом сообщил Росстандарт, а в ГИБДД разъяснили порядок установки таких номеров.
До недавних пор в России были разрешены только автомобильные номера «национального стандарта», что заставляло владельцев иномарок, у машин которых места для крепления номеров не соответствовали ГОСТу, гнуть госномера, крепить их саморезами к кузову. Новый ГОСТ позволяет владельцам японских праворульных и американских машин заказать так называемые «квадратные» номера, размер которых будет совпадать с размером места крепления в задней части кузова, предусмотренного автопроизводителем.
Квадратные номера машины. Фото с сайта drom.ru «У владельцев транспортных средств, обращающихся в регистрационно-экзаменационные подразделения Госавтоинспекции, часто возникали вопросы, касающиеся применения государственных регистрационных знаков нового образца. В частности,такие вопросы наиболее часто возникают у владельцев автомобилей, произведенных в США и Японии, а также ряда моделей мотоциклов, имеющих нестандартные места для установки знаков» — сообщила пресс-служба Госавтоинспекции МВД РФ.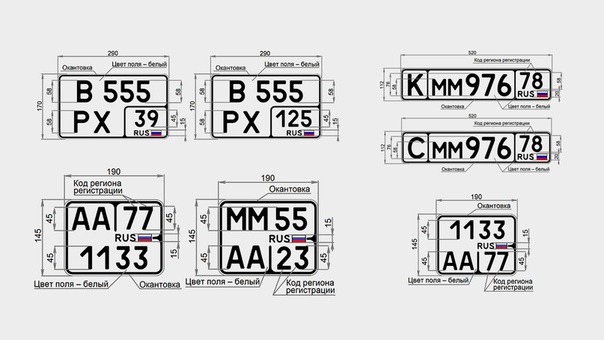
Новый ГОСТ — хорошая новость для автомобилистов Новосибирской области, где доля автопарка подержанных японских автомобилей с правым рулем достаточно высока — регион из года в год входит в пятерку лидеров по количеству таких автомобилей.
По итогам 2018 года в регионе было продано 32 тысячи праворульных машин (по данным агентства «Автостат»).
В Росстандарте приняли решение о вступлении ГОСТа в силу 4 августа 2020 года, но с «правом досрочного применения». Это значит, что уже сейчас применение уменьшенных регистрационных знаков не запрещено.
Номера для мотоциклов. Фото с сайта drom.ru «На сегодняшний день применение уменьшенных регистрационных знаков не запрещено, но они могут быть установлены только на тех транспортных средствах, которые имеют нестандартные места для их установки, что прямо предусмотрено новой редакцией ГОСТ», — сообщила недавно пресс-служба МВД РФ.
Официальный представитель МВД РФ Ирина Волк пояснила, что для изготовления таких знаков владелец автомобиля или мотоцикла может по собственной инициативе обратиться в соответствующую организацию. При этом следует учесть, что указанные знаки могут быть изготовлены организациями, имеющими свидетельство об утверждении изготовленного образца данных типов государственных регистрационных знаков транспортных средств.Напомним, что по закону фирмы, изготавливающие номерные знаки, несут ответственность за умышленное или совершенное по неосторожности искажение регистрационных данных транспортных средств, маркировки транспортных средств и основных их компонентов, а также за нарушение порядка госрегистрации.
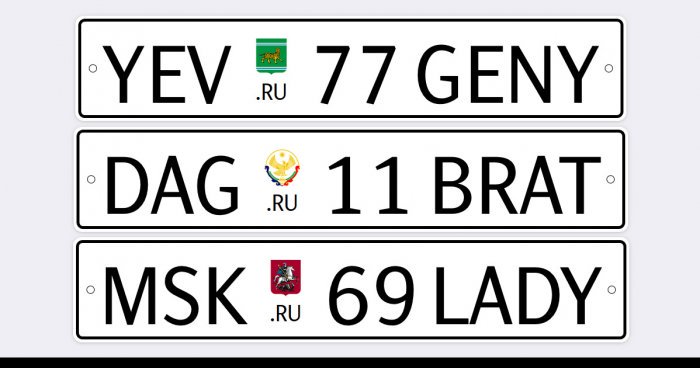
По данным автомобильного портала drom.ru, ГОСТ вводит десять новых типов регистрационных знаков. Самое главное, что среди них есть номера, рассчитанные на американские и японские праворульные автомобили с нестандартным для РФ местом крепления. «Квадратный» номер можно будет заказать только для задней площадки автомобиля, спереди придется использовать обычный номер нынешнего формата. Размер «квадратного» номера — 290 на 170 мм (для сравнения, размеры обычного номера — 520 на 112 мм).
«Мотоциклистам будут доступны номера уменьшенного размера: 190 на 145 мм. У зарубежных мотоциклов маленькая площадка под номер — российский госзнак на нее не помещается. Старый ГОСТ 1993 года этого не учитывал», — сообщает drom.ru.
Для раритетов и машин для автоспорта предусмотрена отдельная категория номеров
— с литерами «К» и «С» соответственно: буквы будут отделены чертой от остальных символов. Спецучет таких машин позволит ввести для них ограничения в правилах движения.
Впервые появляются специальные госзнаки для мопедов, но регистрировать будут только макси-скутеры, которые хоть и не являются полноценными мотоциклами, но оборудованы двигателями объемом более 50 куб. см.
см.
Также ГОСТ регламентирует, что каждая заготовка номера должна иметь уникальный 12-значный код изготовителя. Это необходимо полиции, чтобы знать, где, кем, и когда был произведен госзнак (и где был продан). Помимо этого ГОСТом снят запрет на сверление дополнительных отверстий в знаке: уточнено лишь, что они не должны затрагивать символы, флаг и код RUS.
Видео дня. Как таксисты оккупируют придомовую территорию
Читайте также
auto.rambler.ru
Номера по новому ГОСТу — Toyota Celica, 1.8 л., 2001 года на DRIVE2
«С 1 января 2019 года в соответствии с приказом Росстандарта 555-ст вводится в действие новый ГОСТ «Знаки государственные регистрационные транспортных средств». Разработка документа началась в 2016 году по инициативе Научного центра безопасности дорожного движения МВД РФ»
Кому интересно вот ссылка: www.kommersant.ru/doc/3745670.
ГОСТ Р 50577-2018 дата введения 01.01.2019г.
Но, выдача этих номеров в ГИБДД не началась (… как выяснилось, ГИБДД скоро вообще не будет выдавать «твердые» номера). Однако, ГОСТ вступил в силу, а значит можно заказать такой номер.
Однако, ГОСТ вступил в силу, а значит можно заказать такой номер.
Еще в конце октября 2018 позвонил по конторам, которые занимаются изготовлением дубликатов гос.рег.номеров, ответ был от всех одинаковый: нет заготовок.
Позже увидел пост в Инстаграмме от пользователя Avtonomera_102.ru, списались, сделали заказ на клуб (оптом дешевле). И вот уже в новом году получили свои новые номера. Публикую фотографии клубных машин с разрешения владельцев.
Полный размер
Было. Подсветка номера на рамке давно перестала работать. Номер кажется чужеродным элементом. Знаю, что найти еврорамку на кузов ST20 сложно и дорого.
Полный размер
Стало. Лампочки подсветки номера нужно было просто установить.
Полный размер
Полный размер
квадратный номер на Celica T23 (американка)
Кузов Т23 вполне себе приспособлен для европейского размера номера. Однако, заполучить новый номер «не как у всех» на законных основаниях все же хотелось. Нравится мне номера в японском стиле.

Полный размер
Присмотрел в каталоге дилерских опций рамку под квадратный номер. Точнее не рамку … а, правильно будет сказать, бленду. Бленда конкретно под кузов ZZT23.
Полный размер
внимание справа вверху
Наше бленду на Farpost в магазине eastcar, все в полном комплекте, присутствуют накладки под бленду, чтобы ничего не дребезжало о кузов.
Полный размер
полный комплект
Полный размер
идеальное состояние, ни царапинки. Я даже поверил бы, что это настоящий карбон, наверное
Но транспортная компания ПЭК решила, что груз в обрешетке надо отправлять непременно весь и весь в одной … сотрудники компании ПЭК положили пластиковую рамку, упакованную в пленку, и металлические передние рычаги подвески макферсон в один ящик, ничего внутри не зафиксировав. Естественно, что по пути из Владивостока в Уфу рамка (она же бленда) была сломана почти пополам. Данный факт зафиксировали при получении. Но не будем о грустном. Нашел еще одну бленду, дешевле, но уже не в полном комплекте.
 Бленда очень хрупкая, обязательно заказывайте обрешетку.
Бленда очень хрупкая, обязательно заказывайте обрешетку.Итак, номера — есть, бленда в сборе — есть, можно идти в гараж устанавливать.
Полный размер
небольшой такой номерок
Полный размер
примерка перед установкой
Полный размер
другая рамка. Состояние похуже, но вполне хорошее.
Полный размер
накладки под боковушки, чтобы бленда не била о кузов. Закрепил их на двусторонний скотч
Полный размер
номер пострадал за 10 лет. Рамку клубную аж из Москвы заказывал.
Вот тут надо сделать одно замечание. При заказе мы попросили сделать отверстия в номерах по японскому стандарту(можно заказать номер без отверстий). Примерка на японскую бленду показала, что отверстия сошлись. Отверстия для крепления номера в крышках багажника японки и американки различаются. Так исторически сложилось, что у меня крышка багажника от TRD Sports M, а значит от японской версии Celica.
Полный размер
расстояние между центрами отверстий 208мм. У американки другое расстояние. Внимательный читатель увидел камеру заднего хода вместо лампы подсветки номера.
У американки другое расстояние. Внимательный читатель увидел камеру заднего хода вместо лампы подсветки номера.
Полный размер
вкрутил на болты, которые нашел в гараже. Другого крепежа под рукой не было.
Полный размер
номер с блендой установлен
Полный размер
Полный размер
Результат мне лично понравился. Выглядит необычно. Жаль не додумались сделать такие номера раньше, ведь в СССР были квадратные номера не только на спецтехнике. Теперь езжу по городу и нехотя замечаю «японцев» с «неправильными» номерами)
PS Камеру заднего вида приобрел по совету pravsha на всем известном ресурсе. Показывает вполне сносно, тоже рекомендую к заказу. Установка не сложная, когда весь салон разобран.
Полный размер
имеется полоса вверху от ручки открывания багажника, но обзору не мешает
www.drive2.ru
Номера нового образца — Mitsubishi Legnum, 2.5 л., 2001 года на DRIVE2
Полный размер
Прежде чем начать комментировать прочти:
1. Номер можно вешать ТОЛЬКО на заднюю часть авто при наличии спец. места
Номер можно вешать ТОЛЬКО на заднюю часть авто при наличии спец. места
2. Номера-дубликаты (классические номера у меня остались)
3. Если вы сделаете, как у меня, то не надо мне потом засирать личку, что из-за меня вас посадили на бутылку!
4. На вопрос «если спереди нельзя, то как ты ездишь?» отвечаю, езжу быстро, иногда медленно. Если серьезно, то после ряда случаев мне стало насрать на наше государство, поэтому я буду ездить на чем хочу и как хочу. В планах переделать регистрационные знаки по габаритам японских знаков, потому что мало того, что нашим понадобилось 26 лет на введение квадрата, так еще и по размерам взяли от спец.техники… это называется медвежья услуга.
Если вдруг начнется вновь из серии: «а что на перед тоже можно?» или «так на перед же нельзя», то я создам список товарищей с низким iq и опубликую у себя в БЖ. Спасибо.
Что касается последней фотки, нет, я не забыл заправиться, просто не вижу смысла стоять в очереди на колонку с 98 бензином, когда там стоит очередное чмо на говносолярисе и заливает 92 бензин, ему же на соседней не заправится, это лишние 3 метра идти… в общем звоню, приезжают, наликом или переводом кидаю денег и еду дальше, очень удобно, комфортно и классно:)))
Полный размер
Полный размер
Полный размер
Полный размер
Полный размер
Полный размер
Полный размер
Полный размер
www. drive2.ru
drive2.ru
Сообщества › Это интересно знать… › Блог › Какими будут новые номерные знаки для автомобилей и мотоциклов
В 2019 году вводятся в обращение новые виды номерных знаков для мотоциклов, японских праворульных машин, мопедов, квадроциклов. В перспективе собственные регистрационные знаки появятся у скутеров, классических и ретро автомобилей. В подробностях разбирался «Ъ».
Речь идет о новом стандарте «Знаки государственные регистрационные транспортных средств. Типы и основные размеры. Технические требования» (ГОСТ 50577-2018). Главный разработчик документа — Научный центр безопасности дорожного движения МВД. Предложения поступали от ГИБДД, Минобороны, Минсельхоза, Российской автомобильной федерации, общественных организаций. Стандарт утвержден приказом Росстандарта 555-СТ от 4 сентября, с 1 января 2019 года он вступает в силу.
Новые виды номеров
1) Задний номер для площадок с нестандартным местом крепления. Обычные прямоугольные регистрационные знаки (520 на 112 мм) в такие места не влезают, их приходится сгибать или использовать переходники. С этой проблемой постоянно сталкиваются владельцы праворульных японских авто и некоторых американских машин, ввезенных в Россию «серым» способом. Новые номера избавляют автовладельцев от этой проблемы.
С этой проблемой постоянно сталкиваются владельцы праворульных японских авто и некоторых американских машин, ввезенных в Россию «серым» способом. Новые номера избавляют автовладельцев от этой проблемы.
1
2) Новый номер для мотоциклов. Действующий стандарт — 245 на 160 мм, новый — 190 на 145 мм. Изменение размера должно решить проблему установки номеров на зарубежные модели мотоциклов: у них, как правило, небольшая площадка под госзнак, российские номера на них плохо держатся, их может сорвать на ветру. Приходится использовать самопальные переходники.
2
3) Номер для мопедов и квадроциклов. В случае с «мопедным» номером речь идет так называемых макси-скутерах, владельцы которых сталкиваются с теми же проблемами, что и байкеры: слишком большой номер не помещается на маленькую площадку. Для них и вводится новый компактный знак. Тоже самое — с квадроциклами (их, кстати, регистрируют не в ГИБДД, а в Гостехнадзоре). Что касается традиционных мопедов и скутеров (с объемом двигателя менее 50 куб. см и максимальной скоростью менее 50 км\ч), то сначала нужно ввести законодательную обязанность регистрировать их в ГИБДД. Такая возможность в ГОСТе заложена, но сугубо теоретическая, какой-либо конкретики на этот счет нет.
см и максимальной скоростью менее 50 км\ч), то сначала нужно ввести законодательную обязанность регистрировать их в ГИБДД. Такая возможность в ГОСТе заложена, но сугубо теоретическая, какой-либо конкретики на этот счет нет.
3
Слева — новые знаки для для внедорожных мототранспортных средств (квадроциклы и т.д.) справа — для мопедов
Слева — новые знаки для для внедорожных мототранспортных средств (квадроциклы и т.д.) справа — для мопедов
4) Номера для ретро (классических — с буквой К) и спортивных автомобилей (с буквой С). Появление таких регистрационных знаков — первый этап реформы, целью которой является закрепление особого юридического статуса ретро и спортивных авто. Российская автомобильная федерация предлагает ввести специальные правила регистрации таких машин и, в перспективе, особые правила движения по дорогам общего пользования. Это практика многих зарубежных странах: старинным автомобилям, к примеру, может быть запрещено выезжать на хайвэй, ездить по ночам и разгоняться выше определенной скорости из соображений безопасности. Но до тех пор, пока ретро и спортивные машины регистрируют в ГИБДД, как обычные машины, специальные номера выдавать на них не будут, об этом прямо сказано в ГОСТе.
Но до тех пор, пока ретро и спортивные машины регистрируют в ГИБДД, как обычные машины, специальные номера выдавать на них не будут, об этом прямо сказано в ГОСТе.
4
Передний номер для классических и спортивных автомобилей
5
Номера для ретро и спортивных мотоциклов
6
Задний номер для «классики». Подойдет, к примеру, для ГАЗ-69 или 401-го «Москвича»
6) Номера для мотоциклов, зарегистрированных на работников дипмиссий. Иностранцы, работающие в посольствах и консульствах, пользуются определенным иммунитетом, поэтому инспектор ГИБДД должен четко понимать, что в потоке едет дипломат на двухколесной технике. Потребность в таких номерах возникла, скорее всего, из-за увеличения числа мотоциклов на дорогах, в том числе, управляемых иностранцами. Кстати, в 90-е ГИБДД использовала желтые номера для машин и мотоциклов экспатов, проживающих в России. Но в начале 2000-х в ГОСТ были внесены изменения, и желтый фон на регистрационных знаках стали использовать для обозначения автобусов, троллейбусов и такси.
7
Источник
www.drive2.ru
Nissan Cefiro Quality Excellence › Бортжурнал › Наконец то! Дождались! Квадратные номера для японских и американских автомобилей!
Никогда бы не подумал что буду делать записи про простые бытовые житейские дела, но это очень значимое событие! Во первых можно наконец то будет избавится от дикого колхоза на заднем бампере, что прибавит +100500% к стилю и внешнему виду вообщем! Во вторых, наконец то будет смысл починить подсветку заднего номера! Я даже не представляю как она светит на цефирах, в жизни не видел чтоб у кого то она горела!🤣
Оф.источник гибдд.ру опубликовал у себя на сайте новость! Что с 1 января 2019 года вводится новый стандарт номерных знаков для автомобилей, мотоциклов и техники.
На сайте отмечено, что уже зарегистрированные АМ смогут получить новые таблички в местах изготовления номерных знаков. Другими словами, 1 января все маршируем в пункт изготовления дубликатов, для получения квадрата! Ура! Не смотря на то что это выходной день, все равно иду!)) в ноч с 1-го по 2-е января отмечаем это событие всей страной!
Единственное что жаль, это то, что можно будет получить только один номер и только для заднего бампера. Передний номер остается таким, каким был. Конечно же большей части японоводов захочется и передний номер квадратной формы. Он лучше вписывается и не загораживает возможные вентиляционные отверстия обдува радиатора. Как одобрят установку передней таблички квадратной формы не известно. Единственное что еще можно добавить, то что не совсем новые номера по японскому госту размера. Высота совподает, 170мм. А ширина будет меньше на 4 см! Вместо японских 33см, будет 29см русских. Поэтому где брать красивые рамки под номер пока не понятно. И естественно назревает вопрос о том, где же на номере будут крепежные отверстия. На японском бампере они находятся сверху номера, с определенным расстоянием между отверстиями. Не нужно верить что они совпадут на новых номерах. Поэтому вопрос с креплением будет сразу стоять перед человеком
Передний номер остается таким, каким был. Конечно же большей части японоводов захочется и передний номер квадратной формы. Он лучше вписывается и не загораживает возможные вентиляционные отверстия обдува радиатора. Как одобрят установку передней таблички квадратной формы не известно. Единственное что еще можно добавить, то что не совсем новые номера по японскому госту размера. Высота совподает, 170мм. А ширина будет меньше на 4 см! Вместо японских 33см, будет 29см русских. Поэтому где брать красивые рамки под номер пока не понятно. И естественно назревает вопрос о том, где же на номере будут крепежные отверстия. На японском бампере они находятся сверху номера, с определенным расстоянием между отверстиями. Не нужно верить что они совпадут на новых номерах. Поэтому вопрос с креплением будет сразу стоять перед человеком
Полный размер
Полный размер
www.drive2.ru
Новые автомобильные номера в России 2019
С 4 августа текущего года в России стали выдаваться номера гос регистрации автомобилей нового образца. Именно этот день и является датой, когда в силу вступает закон про государственную регистрацию транспортных средств. Кроме того, с этого момента производством гос табличек займутся коммерческие частные компании.
Именно этот день и является датой, когда в силу вступает закон про государственную регистрацию транспортных средств. Кроме того, с этого момента производством гос табличек займутся коммерческие частные компании.
Согласно приказу, теперь существует 10 типов номерных табличек. Они предусмотрены для установки на всевозможные транспортные средства: мотоциклы, квадроциклы, авто с японского и американского рынка, транспорт, имеющий квадратное место для установки номерного знака, ретроавто и даже спорт кары.
Для чего нужны изменения?
Новый тип номерных знаков имеет двадцатизначный код производителя таблички о гос регистрации автомобиля. Благодаря его наличию теперь инспекторы могут понять, кто, где и когда изготовил дубликат номерного знака авто или же оригинал номера.
Более того теперь стало несколько проще еще и с установкой автономера. Согласно новому ГОСТу, в номерной табличке теперь можно сверлить отверстия для удобства. Самое важное, при этом нельзя повредить флаг и буквы.
Целью всех произведенных нововведений является облегчение жизни владельцам автомобилей. Всем любителям автотранспорта, которые не имеют европейской площадки, теперь не придется проявлять чудеса воображения для того, чтобы прикрепить дубликат номера гос регистрации.
Кроме того, новые таблички стали ровными, а не вогнутыми, как было раньше. Благодаря этому они теперь лучше считываются автомобильными радарами.
Надо ли менять старый номер на новый?Пока номерные таблички нового образца выдаются автомобилям, которые по каким-либо причинам проходят перерегистрацию или же регистрируются в первый раз.
Получить новый номер при необходимости или желании можно в соответствующем государственном органе. Однако, в этом случае, придется собрать достаточно внушительный объем документов, отстоять длинные и утомительные очереди, а также, вероятно, столкнуться с бюрократией.
Но, выход из такой ситуации тоже есть: можно обратиться к частным компаниям, которые имеют разрешающие документы на деятельность, а также нужные лицензии.
Компания AVTOZNAK изготовит дубликат номерной таблички в максимально сжатые сроки. Более того, для того, чтобы начать изготавливать табличку, нам нужно всего три документа:
- Паспорт или документ, удостоверяющий личность;
- Водительское удостоверение;
- Свидетельство про регистрацию транспортного средства.
Как только весь нужный пакет документов будет у нас, мы можем сразу же начать изготовление номерного знака. Кроме того, на весь процесс производства у нас уходит до одного часа: с момента принятия заявки до момента отдачи готового результата.
Как оставить заявку в компании AVTOZNAK?
Для наших клиентов мы предлагаем максимальное количество удобных вариантов. Оставить заявку на производство дубликата номера гос регистрации можно тремя способами:
- Лично приехать к нам в офис. При этом, можно уже иметь при себе нужные документы и тогда получится сразу уехать с уже готовой табличкой номера гос регистрации.
- Позвонить нам по номерам, которые указаны у нас на сайте.

- Оставить свои контактные данные в форме обратной связи на сайте, чтобы мы могли связаться с вами как можно быстрее.

При этом, если приехать лично возможности вообще нет, то даже все документы можно отправить нам, компании AVTOZNAK по электронной почте, в хорошем качестве через скан.
Доставка готового номера гос регистрации автомобиля американской или японской марки возможна курьером по всей территории страны.
Легальные услуги от компании AVTOZNAK по изготовлению номеров нового образца
Наша компания производит гос номера нового образца для авто японских и американских авто за считанные минуты. Уже более пяти лет действует закон, разрешающий негосударственным коммерческим компаниям создавать дубликаты номерных знаков. Именно поэтому, сегодня получить дубликат гос номера регистрации стало быстрее и проще.
Обращаясь к нашей компании, каждой клиент получит:
- Достойный уровень обслуживания;
- Качественный сервис;
- Быстрое производство изделия;
- Гарантию, на изготовленный номерной знак.
Мы работаем только на высокотехничном оборудовании, благодаря чему можем давать гарантию на произведенные изделия. Кроме того, в нашей компании слажено работают только опытные сотрудники, что позволяет нам обрабатывать и выполнять заказы как можно быстрее.
Наша компания AVTOZNAK — это проверенный производитель, который имеет разрешающие документы и соответствующую лицензию для изготовления дубликатов номерных табличек гос номеров нового образца для авто японских и американских марок.
dublikat-gos-nomera-spb.ru
опубликованы первые изображения — Сообщество «DRIVE2 и ГАИ» на DRIVE2
В сеть попали эскизы, которые могут стать основой для государственных регистрационных знаков нового образца
Напомним, что научно-исследовательский центр проблем безопасности дорожного движения начал разработку новой редакции госстандарта для номерных знаков: разработка обновленной версии документа оказалась необходима из-за ряда накопившихся проблем.
Возможные варианты мотономеров нового образца. Иллюстрация: Carscope.ru
Иллюстрация: Carscope.ru
Полный размер
…
Так, большинство мотоциклов имеют меньшую по размерам площадку для номера, чем российский знак. Соответственно, в новой редакции ГОСТа планируется пересмотреть размеры мотоциклетных номеров. Кроме того, в НИЦ хотят ввести знаки квадратной формы для японских и американских автомобилей.
Полный размер
.
Проект специальных номеров для классических (отмечены буквой «К») и спортивных («С») автомобилей. Иллюстрация: Carscope.ru
Полный размер
.
По информации портала Carscope, в настоящее время предлагается несколько вариантов того, какими могут стать госномера. В частности, рассматривается возможность переноса кода региона из правой части номера налево. Другой вариант — полный отказ от указания региона.
Номера квадратной формы для «японцев» и «американцев». Иллюстрация: Carscope.ru
Полный размер
…
Для классических, спортивных транспортных средств, а также мопедов и велосипедов могут ввести отдельные типы регистрационных знаков.
 Кроме того, обсуждается возможность введения полимерных знаков вместо металлических и размещение на номерах микрочипов радиочастотной фиксации.
Кроме того, обсуждается возможность введения полимерных знаков вместо металлических и размещение на номерах микрочипов радиочастотной фиксации.Такими могут стать номера для легковых и грузовых автомобилей, а также автобусов. Иллюстрация: Carscope.ru
Полный размер
…
Кстати, в НИЦ хотят, как минимум, указать конкретные места на регистрационных знаках, где можно сверлить отверстия: сегодня «дырявить» номера запрещено, однако на многих иномарках не удаётся закрепить таблички другим способом.
Такими могут стать номера для мопедов и велосипедов
Пересмотр ГОСТ-50577 предусмотрен планом по стандартизации на 2017 год. Публичное обсуждение первой редакции стандарта начнётся осенью 2017 года, окончательная редакция будет готова весной 2018 года, а утверждение нацстандарта запланировано на октябрь 2018 года.
источник auto.mail.ru/article/6300…any_pervye_izobrazheniya/
www.drive2.ru
Номера нового образца — DRIVE2
Всерьез начали говорить про замену автономеров в РФ. Давно пора. СМИ уже говорят, что не только начали говорить, но и начались телодвижения к созданию нового ГОСТа и нормативных документов. Даже указана дата воплощения в жизнь: конец 2018 года. То есть не за горами. Увидел прототипы этих номеров. Не факт, что подлинники, может и какой то журналист нафотошопил, но как то так:
Давно пора. СМИ уже говорят, что не только начали говорить, но и начались телодвижения к созданию нового ГОСТа и нормативных документов. Даже указана дата воплощения в жизнь: конец 2018 года. То есть не за горами. Увидел прототипы этих номеров. Не факт, что подлинники, может и какой то журналист нафотошопил, но как то так:
Полный размер
Номера для спортсменов и коллекционеров и любителей ретро. Правильная вещь, давно пора. Главное, что бы в итоге в регламенте их использования были человеческие ограничения. А то ограничат время нахождения на общественных дорогах только днем, скорость, жилую зону и добавят еще какой либо пункт, что не нарушив его не доедешь из пункт А в пункт Б на соседнюю улицу.
Ходят идеи изменить расположение символов:
Полный размер
Почему нельзя полностью нарисовать знаки с белого листа? Возможно сделать шрифт другой, с защитой от подделывания, на подобии, как на знаках немецкого типа, изменить размер, коды региона и т.п. наверняка есть полезный опыт других стран, которые можно проанализировать и взять от них лучшее.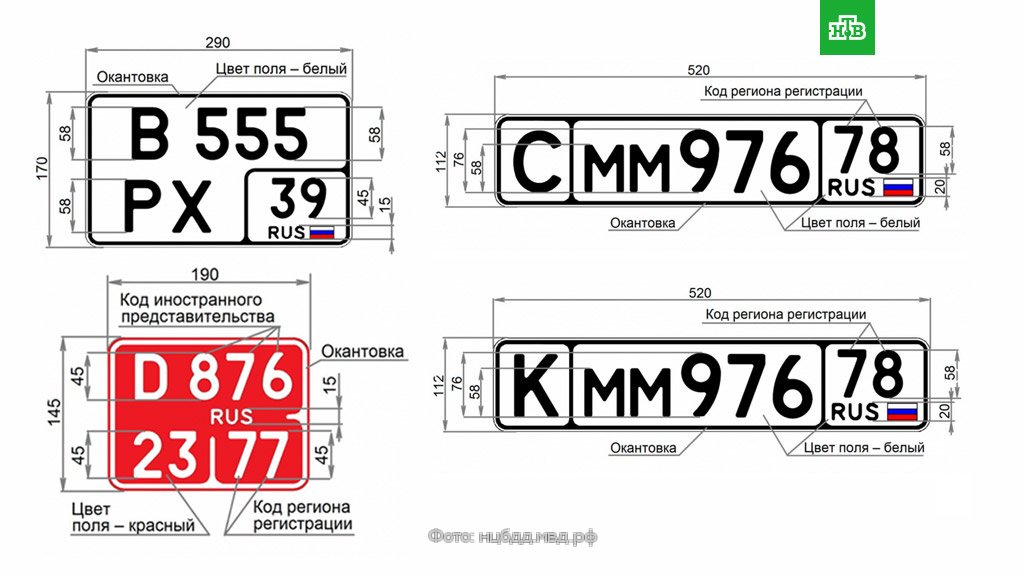 Так же учитывать мнение камер фиксации скорости, им тоже наверняка много что не нравится. Пока я вижу нерациональное использование площади знака в этих примерах, кашу в интервалах, читаемости и т.д.
Так же учитывать мнение камер фиксации скорости, им тоже наверняка много что не нравится. Пока я вижу нерациональное использование площади знака в этих примерах, кашу в интервалах, читаемости и т.д.
Полный размер
«Квадратные знаки» . Я, как владелец праворуких японцев больше всего жду их.
Мотоциклисты тоже будут рады. Блин, самый маленький походу дела велосипедный, 12 на 14 сантиметров) Кроха же! :
Полный размер
Полный размер
Кстати, почему то не говорят об именных номерах? Выбрал подходящее сочетание букв, цифр, узнал цену, заплатил онлайн картой, получил по почте номера. Где это все?
www.drive2.ru
Номера нового образца: опубликованы первые изображения
23 нояб. 2016 г., 14:15
В сеть попали эскизы, которые могут стать основой для государственных регистрационных знаков нового образца
Напомним, что научно-исследовательский центр проблем безопасности дорожного движения начал разработку новой редакции госстандарта для номерных знаков: разработка обновленной версии документа оказалась необходима из-за ряда накопившихся проблем.
Так, большинство мотоциклов имеют меньшую по размерам площадку для номера, чем российский знак. Соответственно, в новой редакции ГОСТа планируется пересмотреть размеры мотоциклетных номеров. Кроме того, в НИЦ хотят ввести знаки квадратной формы для японских и американских автомобилей.
По информации портала Carscope, в настоящее время предлагается несколько вариантов того, какими могут стать госномера. В частности, рассматривается возможность переноса кода региона из правой части номера налево. Другой вариант — полный отказ от указания региона.
Для классических, спортивных транспортных средств, а также мопедов и велосипедов могут ввести отдельные типы регистрационных знаков. Кроме того, обсуждается возможность введения полимерных знаков вместо металлических и размещение на номерах микрочипов радиочастотной фиксации.
Кстати, в НИЦ хотят, как минимум, указать конкретные места на регистрационных знаках, где можно сверлить отверстия: сегодня «дырявить» номера запрещено, однако на многих иномарках не удаётся закрепить таблички другим способом.
Пересмотр ГОСТ-50577 предусмотрен планом по стандартизации на 2017 год. Публичное обсуждение первой редакции стандарта начнётся осенью 2017 года, окончательная редакция будет готова весной 2018 года, а утверждение нацстандарта запланировано на октябрь 2018 года.
По материалам сайта auto.mail.ru
Источник: http://in-reutov.ru/novosti/transport/nomera-novogo-obrazca-opublikovany-pervye-izobrazheniya
Утверждены автомобильные регистрационные знаки нового образца
Наши читатели присылают фотографии с автомобильными номерами, которых раньше в Беларуси не видели. Вроде все как и прежде: белый фон, черные символы, флаг, обозначение BY. Вот только BY — зеленого цвета. Мы стали выяснять, что это за необычные регистрационные знаки. Оказалось — теперь так выглядят белорусские автомобильные номера нового образца.
Мы привыкли к тому, что требования к автомобильным регистрационным знакам, выдаваемым на территории Беларуси, определены государственным стандартом СТБ 914-99. Там четко прописано, какие цифры и буквы, какой шрифт, цвет, расстояние между символами могут использоваться — в общем, все.
И номера, которые то и дело замечают на автомобилях, почти такие же, как и прежде. Видимая разница лишь в цвете обозначения BY — с черного он сменился на зеленый.
Были предположения, что такие номера выдают автомобилям на экологичном топливе — на газу. Однако в реальности все еще масштабнее.
— Были внесены изменения в СТБ. Это регистрационные знаки нового образца, — сообщила корреспонденту Onliner начальник отдела агитации и пропаганды ГАИ Минска Александра Попова.
Ранее мы сообщали о том, что в Беларуси были введены зеленые номера для электромобилей. На них все символы зеленого цвета. Новая норма зафиксирована в изменениях в СТБ 914-99 «Знаки регистрационные и знак отличительный транспортных средств», утвержденных постановлением Госкомитета по стандартизации РБ от 12 декабря 2019 г. №70. Изменения вступили в силу 1 июля. Новые регистрационные знаки предназначены для различных категорий электромобилей (легковые, грузовые автомобили, автобусы) и мототранспортных средств, приводимых в движение электродвигателем.
№70. Изменения вступили в силу 1 июля. Новые регистрационные знаки предназначены для различных категорий электромобилей (легковые, грузовые автомобили, автобусы) и мототранспортных средств, приводимых в движение электродвигателем.
Знакомы с ситуацией? Пишите нам: [email protected].
Auto.Onliner в Telegram: обстановка на дорогах и только самые важные новости
Есть о чем рассказать? Пишите в наш Telegram-бот. Это анонимно и быстро
МВД разъяснило ситуацию с выдачей автомобильных номеров нового образца :: Общество :: РБК
Несмотря на то, что новый стандарт на размеры автомобильных и мотоциклетных номеров вступит в силу только в 2020 году, некоторые владельцы транспортных средств могут использовать регистрационные знаки нового типа уже сейчас. Об этом заявила официальный представитель МВД России Ирина Волк.
Об этом заявила официальный представитель МВД России Ирина Волк.
По ее словам, с вопросами о возможности использования номеров нового образца в подразделения Госавтоинспекции обычно обращаются хозяева автомобилей японского и американского производства, а также выпущенных за границей мотоциклов. Первые заинтересованы в установке на задние площадки машин двухстрочных регистрационных знаков, так как обычный однострочный на них не помещается, а вторые — в меньших по сравнению с действующим стандартом (245×185 мм) номерах нового образца (190×145 мм).
«На сегодняшний день применение уменьшенных регистрационных знаков не запрещено, но они могут быть установлены только на тех транспортных средствах, которые имеют нестандартные места для их установки, что прямо предусмотрено новой редакцией ГОСТ», — пояснила Волк.
По ее словам, владелец соответствующего этому требованию автомобиля или мотоцикла может заказать уменьшенный номер в организации, имеющей «свидетельство об утверждении изготовленного образца данных типов государственных регистрационных знаков транспортных средств».
Подразделения же Госавтоинспекции, по словам Волк, до вступления в силу нового стандарта будут выдавать государственные регистрационные знаки, соответствующие положениям действующего национального стандарта.
Номер для мотоцикла Нового образца (маленький) ГОСТ 50577–2018 тип 4. комплект 1 шт (Дубликат)
ОФИЦИАЛЬНОЕ ИЗГОТОВЛЕНИЕ ДУБЛИКАТОВ ГОС НОМЕРОВ всех видов
Российские номера любого типа, дубликаты более 40 зарубежных стран и сувенирные номера любого дизайна.
Ситуаций, когда возникает необходимость воспользоваться данной услугой, может быть множество: повреждение при ДТП, естественный износ (царапины, вмятины, трещины, ржавчина) в результате долгого пользования, утеря вследствие частых поездок по пересеченной местности, кража с целью получения выкупа, порча под воздействием непогоды и т. д. В нашей компании вы можете приобрести не только номерные таблички на свой транспорт, а так же авто и мото рамки. В продаже имеются рамки для автомобильных и мото номеров — пластиковые, металлические, силиконовые, черные, белые, цветные, с надписями и индивидуальным дизайном. Доставка осуществляется курьером по Москве и Московской области, транспортными компаниями по России и странам СНГ.
д. В нашей компании вы можете приобрести не только номерные таблички на свой транспорт, а так же авто и мото рамки. В продаже имеются рамки для автомобильных и мото номеров — пластиковые, металлические, силиконовые, черные, белые, цветные, с надписями и индивидуальным дизайном. Доставка осуществляется курьером по Москве и Московской области, транспортными компаниями по России и странам СНГ.
Изготовление дубликатов гос. рег номеров
Изготовление дубликатов автомобильных номерных знаков (гос. номеров) на любой вид транспорта с доставкой по Москве и по всей России. Официальная лицензия МВД. Всего по 2 документам.
При заказе номера у нас вы можете быть спокойны о качестве и надежности номерных знаков. Для изготовления номеров мы используем профессиональное оборудование, которое имеет все необходимые лицензии для производства государственных номерных знаков строго по ГОСТ 50577–2018 / ГОСТ Р-50577-93.
Наша компания осуществляет доставку по Москве и области,
по всем регионам России и другие страны — транспортной службой СДЕК.
Чтобы обеспечить выполнение заказа в день заявки, мы используем эффективное сертифицированное оборудование. Аналогичное оборудование используется при изготовлении гос номеров для ГИБДД. Оно позволяет сделать автономер любого типа в полуавтоматическом режиме. Включая предварительную подготовку, на это будет потрачено не более 10 минут.
В соответствии с требованиями ГОСТ, выполняется:
- Выдавливание символов на заготовке в гидравлическом прессе ПГС-Т30М под давлением 10 МПА
- Нанесение покрытия в термокрасочной машине Т240М при оптимальной температуре нагретого барабана ~200-205 °C .
В качестве основы выбираются прочные металлические пластины с высоким пределом износостойкости. Они выдерживают силу механического воздействия, не боятся влияния природных факторов. Качественной является и краска. Для окраски пластин мы используем импортную немецкую пленку. Она не выгорает и не стирается при длительной эксплуатации.
Изготовление дубликатов номеров НОВОГО образца России и всех стран Мира.
Вам необходим дубликат номера с доставкой? Звоните и заказывайте, мы доставим Ваш номер самым быстрым способом в любой регион России.
Как рассчитать среднее значение выборки (с примерами)
Когда статистики изучают совокупности, они могут взять выборку из более крупной совокупности, чтобы применить статистические вычисления для определения тенденций и прогнозирования результатов для большей совокупности. Среднее значение выборки — это одно из вычислений, которое может сообщить статистикам среднее значение для данного набора данных. Статистики используют выборочное среднее для набора данных, чтобы делать прогнозы относительно стандарта нормальности в данной генеральной совокупности, а выборочное среднее также может использоваться для определения дисперсии, отклонения и стандартной ошибки в наборе данных.В этой статье мы исследуем, что такое среднее значение выборки, дисперсия и стандартная ошибка, и как рассчитать среднее значение выборки.
Подробнее: Узнайте, как стать аналитиком данных
Что такое среднее значение выборки?
Выборочное среднее — это среднее значение набора данных. Среднее значение выборки можно использовать для расчета центральной тенденции, стандартного отклонения и дисперсии набора данных. Среднее значение выборки можно применять для различных целей, включая вычисление средних значений по совокупности.Многие отрасли занятости также используют статистические данные, например:
- Научные области, такие как экология, биология и метеорология
- Медицинские области и фармакология
- Данные и информатика, информационные технологии и кибербезопасность
- Аэрокосмическая и авиационная промышленность
Поля в проектировании и проектировании
Как рассчитать выборочное среднее
Расчет выборочного среднего так же прост, как сложение количества элементов в выборке и последующее деление этой суммы на количество элементов в выборке набор. Для вычисления выборочного среднего с помощью программного обеспечения для работы с электронными таблицами и калькуляторов вы можете использовать формулу:
Для вычисления выборочного среднего с помощью программного обеспечения для работы с электронными таблицами и калькуляторов вы можете использовать формулу:
x̄ = (Σ xi) / n
Здесь x̄ представляет собой выборочное среднее значение, Σ говорит нам добавить, xi относится ко всем Значения X и n обозначают количество элементов в наборе данных.
При вычислении выборочного среднего по формуле вы подставите значения для каждого из символов. Следующие шаги покажут вам, как рассчитать выборочное среднее для набора данных:
- Сложите элементы выборки
- Разделите сумму на количество выборок
- Результат — среднее значение
- Используйте среднее значение, чтобы найти дисперсию
Используйте дисперсию, чтобы найти стандартное отклонение
1.Сложите элементы выборки
Сначала вам нужно будет подсчитать, сколько элементов выборки у вас есть в наборе данных, и сложить общее количество элементов. Давайте посмотрим на пример:
Давайте посмотрим на пример:
Учитель хочет узнать средний балл ученика в его классе. В наборе выборки учителя есть семь различных результатов тестов: 78, 89, 93, 95, 88, 78, 95. Он складывает все оценки и получает сумму 616. Он может использовать эту сумму на следующем шаге, чтобы найти свою выборку. иметь в виду.
2.Разделите сумму на количество выборок
Затем разделите сумму из первого шага на общее количество элементов в наборе данных. Вот как это выглядит на примере учителя:
Учитель использует сумму 616, чтобы найти средний балл. Он делит 616 на семь, поскольку в его наборе данных было семь оценок. Результирующее частное составляет 88.
3. Результат — среднее значение
После деления полученное частное становится вашим средним или средним по выборке.В примере с учителем:
Баллы ученика, которые он подсчитывал, дали среднюю оценку 88%. Вы можете использовать выборочное среднее для дальнейшего расчета дисперсии, стандартного отклонения и стандартной ошибки.
Подробнее: Навыки решения проблем: определения и примеры
4. Используйте среднее значение, чтобы найти дисперсию
Вы можете использовать выборочное среднее в дальнейших вычислениях, найдя дисперсию выборки данных .Дисперсия представляет собой степень разброса каждого из элементов выборки в наборе данных. Чтобы вычислить дисперсию, вы найдете разницу между каждым элементом данных и средним значением. На примере учителя давайте посмотрим, как это работает:
Учитель хочет найти дисперсию оценок своего ученика, поэтому он вычисляет дисперсию, сначала находя разницу между средней оценкой и всеми семью оценками ученика, которые он использовал для поиска. среднее значение:
(78-88, 89-88, 93-88, 95-88, 88-88, 78-88, 95-88) = (-10, 1, 5, 7, 0, — 10, 7).
Затем учитель возводит в квадрат каждую разницу (100, 1, 25, 49, 0, 100, 49) и, как и в случае среднего, складывает все числа и делит на семь. Он получает 324/7 = 46,3, или приблизительно 46. Чем больше дисперсия, тем больше отклоняются данные от среднего.
Он получает 324/7 = 46,3, или приблизительно 46. Чем больше дисперсия, тем больше отклоняются данные от среднего.
5. Используйте дисперсию, чтобы найти стандартное отклонение
Вы также можете взять среднее значение выборки еще дальше, вычислив стандартное отклонение набора выборок. Стандартное отклонение представляет собой нормальный коэффициент распределения для набора данных, и это квадратный корень из дисперсии.Давайте посмотрим на пример:
Учитель использует дисперсию 46, чтобы найти стандартное отклонение: √46 = 6,78. Это число говорит учителю, насколько выше или ниже среднего балла его ученика 88% по любому заданному баллу теста в выборке.
Какова дисперсия выборочного распределения среднего?
Дисперсия набора данных относится к разбросу элементов в наборе выборки. Когда статистики вычисляют дисперсию, они пытаются выяснить, насколько далеко друг от друга находятся элементы при представлении данных на графике. Дисперсия может сказать вам, насколько отличается каждый элемент в выборке. Кроме того, среднее значение выборки, дисперсия, стандартное отклонение и ошибка могут быть проанализированы, чтобы предположить и спрогнозировать результаты и тенденции в отношении совокупности, а также выборки этой совокупности.
Дисперсия может сказать вам, насколько отличается каждый элемент в выборке. Кроме того, среднее значение выборки, дисперсия, стандартное отклонение и ошибка могут быть проанализированы, чтобы предположить и спрогнозировать результаты и тенденции в отношении совокупности, а также выборки этой совокупности.
Связано: Аналитические навыки: определения и примеры
Какова стандартная ошибка среднего значения выборки?
Стандартная ошибка среднего (SEM) или стандартное отклонение показывает, насколько далеко среднее значение выборки от истинного среднего значения генеральной совокупности.Например, в примере с учителем выборка состояла только из одного ученика. Среднее значение выборки, дисперсия и отклонение представляют данные только об этой выборке, а стандартную ошибку можно использовать для сравнения данных выборки со всей генеральной совокупностью.
Например, вся совокупность может быть всем классом, целым 10-м классом или всей совокупностью учащихся.![]() В любой из этих ситуаций стандартная ошибка выборочного среднего будет представлена тем, насколько далеко средний балл учащегося от среднего балла всего населения.
В любой из этих ситуаций стандартная ошибка выборочного среднего будет представлена тем, насколько далеко средний балл учащегося от среднего балла всего населения.
Размер выборки в статистике (как его найти): Excel, формула Кокрана, общие советы
Состав:
- Что такое размер выборки?
- Как найти размер выборки:
Размер выборки — это часть совокупности , выбранная для обследования или эксперимента. Например, вы можете провести опрос о предпочтениях владельца собаки в отношении бренда. Вам не захочется опрашивать всех миллионов владельцев собак в стране (либо потому, что это слишком дорого, либо отнимает много времени), поэтому возьмите размер выборки.Это может быть несколько тысяч владельцев. Размер выборки составляет единиц, представляющих брендов всех владельцев собак. Если вы выберете образец с умом, он будет хорошим представителем.
Когда ошибка может возникать в
Когда вы обследуете только небольшую выборку населения, в вашу статистику закрадывается неопределенность . Если вы можете опросить только определенный процент истинного населения, вы никогда не сможете быть на 100% уверены, что ваша статистика является полным и точным представлением населения.Эта неопределенность называется ошибкой выборки и обычно измеряется доверительным интервалом. Например, вы можете заявить, что ваши результаты находятся на уровне достоверности 90%. Это означает, что если вы будете повторять свой опрос снова и снова, в 90% случаев вы получите те же результаты.
Если вы можете опросить только определенный процент истинного населения, вы никогда не сможете быть на 100% уверены, что ваша статистика является полным и точным представлением населения.Эта неопределенность называется ошибкой выборки и обычно измеряется доверительным интервалом. Например, вы можете заявить, что ваши результаты находятся на уровне достоверности 90%. Это означает, что если вы будете повторять свой опрос снова и снова, в 90% случаев вы получите те же результаты.
Перепись — это когда опрашивается каждый член населения, а не только его выборка.
Наверх
См. Также: Определение размера выборки в одном изображении.
Посмотрите видео или прочтите ниже (также посмотрите живых репетиторов на Chegg.com; Ваши первые 30 минут бесплатны!):
Ссылки, упомянутые в видео:
Таблица 95% ДИ
.
Выборка — это процент от общей численности населения в статистике. Вы можете использовать данные из выборки, чтобы делать выводы о генеральной совокупности в целом. Например, стандартное отклонение выборки можно использовать для аппроксимации стандартного отклонения генеральной совокупности. Определение размера выборки может быть одной из самых сложных задач в статистике и зависит от многих факторов, включая размер вашей исходной совокупности.
Шаг 1: Проведите перепись , если у вас небольшая численность населения. «Небольшое» население будет зависеть от вашего бюджета и временных ограничений. Например, проведение переписи студенческого контингента небольшого частного университета с 1000 студентов может занять день, но у вас может не быть времени на опрос 10000 студентов в большом государственном университете.
Шаг 2: Используйте размер выборки из аналогичного исследования. Скорее всего, ваше исследование уже проводилось кем-то другим. Для поиска исследования вам понадобится доступ к академическим базам данных (обычно доступ есть в вашей школе или колледже). Ловушка: вы будете полагаться на кого-то другого, кто правильно рассчитает размер выборки. Любые ошибки, которые они допустили в своих расчетах, будут перенесены в ваше исследование.
Для поиска исследования вам понадобится доступ к академическим базам данных (обычно доступ есть в вашей школе или колледже). Ловушка: вы будете полагаться на кого-то другого, кто правильно рассчитает размер выборки. Любые ошибки, которые они допустили в своих расчетах, будут перенесены в ваше исследование.
Шаг 3: Используйте таблицу , чтобы определить размер вашей выборки. Если у вас есть довольно общее исследование, то, вероятно, для него есть таблица. Например, если у вас есть клиническое исследование, вы можете использовать таблицу, опубликованную в Machin et.Таблицы размера выборки для клинических исследований Эла, третье издание, .
Шаг 4: Воспользуйтесь калькулятором размера выборки. В Интернете доступны различные калькуляторы, некоторые простые, некоторые более сложные и специализированные. Например, этот калькулятор предназначен для групповых или кластерных рандомизированных исследований (GRT).
Шаг 5: Используйте формулу . В зависимости от того, что вы знаете (или не знаете) о своем населении, вы можете использовать множество различных формул. Если вам известны некоторые параметры вашей популяции (например, известное стандартное отклонение), вы можете использовать описанные ниже методы.Если вы мало знаете о своем населении, воспользуйтесь формулой Словина.
В зависимости от того, что вы знаете (или не знаете) о своем населении, вы можете использовать множество различных формул. Если вам известны некоторые параметры вашей популяции (например, известное стандартное отклонение), вы можете использовать описанные ниже методы.Если вы мало знаете о своем населении, воспользуйтесь формулой Словина.
К началу
Формула Кохрана позволяет рассчитать идеальный размер выборки с учетом желаемого уровня точности, желаемого уровня достоверности и предполагаемой доли атрибута, присутствующего в генеральной совокупности.
ФормулаКокрана считается особенно подходящей в ситуациях с большими популяциями. Выборка любого заданного размера дает больше информации о меньшей совокупности, чем о более крупной, поэтому существует «поправка», с помощью которой число, указанное по формуле Кокрана, может быть уменьшено, если вся совокупность относительно мала.
Формула Кохрана:
Где:
- e — желаемый уровень точности (т. Е. Предел погрешности),
- p — (оценочная) доля населения, имеющего рассматриваемый признак,
- q равно 1 — п.
 Е. Предел погрешности),
Е. Предел погрешности),Z-значение находится в Z-таблице.
Пример формулы Кокрана
Предположим, мы проводим исследование жителей большого города и хотим выяснить, сколько семей подают завтрак по утрам.Для начала у нас не так много информации по этому вопросу, поэтому мы предполагаем, что половина семей подают завтрак: это дает нам максимальную вариативность. Итак, p = 0,5. Теперь предположим, что нам нужно 95% уверенности и не менее 5% (плюс-минус) точности. Уровень достоверности 95% дает нам значение Z, равное 1,96, в соответствии с обычными таблицами, поэтому мы получаем
.((1,96) 2 (0,5) (0,5)) / (0,05) 2 = 385,
Таким образом, случайной выборки из 385 домашних хозяйств в нашей целевой группе должно быть достаточно, чтобы дать нам необходимый уровень достоверности.
Модификация формулы Кохрана для расчета размера выборки в небольших популяциях
Если мы изучаем небольшую совокупность, мы можем изменить размер выборки, рассчитанный по приведенной выше формуле, с помощью следующего уравнения:
Здесь n 0 — это рекомендация Кохрана по размеру выборки, N — размер генеральной совокупности, а n — новый скорректированный размер выборки. В нашем предыдущем примере, если бы в целевой группе было всего 1000 домохозяйств, мы бы вычислили
В нашем предыдущем примере, если бы в целевой группе было всего 1000 домохозяйств, мы бы вычислили
385 / (1+ (384/1000)) = 278
Итак, для этого небольшого населения все, что нам нужно, это 278 домашних хозяйств в нашей выборке; существенно меньший размер выборки.
Вернуться к началу
Во второй части показано, как найти размер выборки для заданного доверительного интервала и ширины (например, интервал 95%, ширина 6%) для неизвестного стандартного отклонения совокупности .
Пример вопроса : 41% жителей Джексонвилля сказали, что они попали в ураган. Сколько взрослых следует опросить, чтобы оценить истинную долю взрослых, пострадавших от урагана, с 95% доверительным интервалом шириной 6%?
Шаг 1: Используя данные, приведенные в вопросе, определите следующие переменные:
Шаг 2: Умножить на. Отложите это число на мгновение.
0,41 × 0,59 = 0,2419
Шаг 3: Разделите Z a / 2 на E .
1,96 / 0,03 = 65,3333333
Шаг 4: Квадрат Шаг 3 :
65,3333333 × 65,3333333 = 4268,44444
Шаг 5: Умножение Шага 2 на Шаг 4:
0,2419 × 4268,44444 = 1,032,53671
= 1033 человека для опроса .
Вернуться к началу
Как найти размер выборки с учетом доверительного интервала и ширины (известное стандартное отклонение генеральной совокупности)
Часть 3 показывает вам, как определить соответствующий размер выборки для заданного доверительного интервала и ширины , при условии, что вы знаете генеральную совокупность , стандартное отклонение .
Пример вопроса. Предположим, мы хотим узнать средний возраст студента колледжа штата Флорида плюс-минус 0,5 года. Мы хотим быть уверены в своем результате на 99%.Из предыдущего исследования мы знаем, что стандартное отклонение для населения составляет 2,9.
Мы хотим быть уверены в своем результате на 99%.Из предыдущего исследования мы знаем, что стандартное отклонение для населения составляет 2,9.
Шаг 1: Найдите z a / 2 , разделив доверительный интервал на два и просмотрев эту область в z-таблице:
.99 / 2 = 0,495. Ближайший z-показатель для 0,495 — 2,58 .
Шаг 2: Умножьте шаг 1 на стандартное отклонение.
2,58 * 2,9 = 7,482
Шаг 3: Разделите Шаг 2 на погрешность.Наша погрешность (из вопроса) составляет 0,5.
7,482 / 0,5 = 14,96
Шаг 4: Квадрат Шаг 3.
14,96 * 14,96 = 223,8016
Вот и все! Нравится объяснение? Ознакомьтесь с нашей книгой по статистике с практическими рекомендациями по каждому типу задач элементарной статистики.
Наверх
Посмотрите видео, чтобы узнать, как определить размер выборки, если вы хотите оценить средние значения:
 youtube.com/embed/k1lgneXc2nw» title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/k1lgneXc2nw» title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Не можете посмотреть видео? Кликните сюда.
Посмотрите видео или прочтите следующие шаги:
Как использовать выборку Excel для поиска образца
Если у вас есть набор данных и вы знаете размер выборки, вы можете использовать пакет инструментов Excel для анализа данных, чтобы выбрать периодическую или случайную выборку. Случайная выборка — это всего лишь случайная выборка из вашего набора данных. Периодическая выборка (также называемая систематической выборкой) — это когда Excel выбирает n-й элемент данных для включения в вашу выборку. Например, если вы хотите выбрать каждое 5-е число из следующего списка: 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, Excel вернет 8 и 13 (5-е и 10-е числа чтобы).
Если вы не знаете, какой размер выборки вам нужен, рассчитайте его перед использованием инструмента анализа данных (используя методы, описанные в верхней части этой статьи). Инструмент анализа данных может помочь вам извлечь образец, но не поможет вам выбрать размер . Почему? Существует множество «человеческих» факторов, влияющих на выбор размера выборки, включая бюджет, предыдущие исследования (вы можете использовать размер выборки из предыдущего исследования) и таблицы, составленные из предыдущих исследований.
Как использовать выборку Excel для поиска образца: шаги
Шаг 1: Введите элементы данных в Excel.Вы можете вводить свои данные в строки или столбцы. Убедитесь, что строки и столбцы ровные; например, введите данные в столбец A в ячейку 12 и столбец B в ячейку 12.
Шаг 2: Щелкните «Данные», а затем «Анализ данных». Если вы не видите Анализ данных на панели инструментов, загрузите пакет инструментов анализа данных.
Шаг 3: Щелкните «Выборка», а затем «ОК».
Данные, введенные в рабочий лист для выборки Excel: строки и столбцы четные.
Шаг 4. Щелкните поле «Диапазон ввода» и выберите весь набор данных.
Шаг 5: Щелкните «Периодическая выборка» или «Случайная выборка». Если вы выбираете периодический, введите n-е число (т.е. каждые 5), а если вы выберете случайную выборку, введите размер выборки.
Шаг 6: Выберите выходной диапазон. Например, нажмите кнопку «Новый лист», и Excel вернет образец на новом листе.
Шаг 7: Нажмите «ОК».
Вот и все!
Посетите наш канал YouTube, чтобы получить больше советов и помощи по Excel!
К началу
Статьи по теме
способов уменьшить размер выборки.
Эффективный размер выборки.
Неравный размер выборки.
Список литературы
Bartlett, J. et al. (2001). Организационные исследования: определение подходящего размера выборки в опросных исследованиях. Получено 15 января 2018 г. с: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.486.8295&rep=rep1&type=pdf.
Evans, M .; Hastings, N .; и Пикок, Б. Статистические распределения, 3-е изд. Нью-Йорк: Wiley, 2000.
Israel, G. (n.d.) Определение размера выборки. Расширение МФСА Университета Флориды.Статья размещена на сайте Тарлтонского государственного университета. Получено 13 января 2018 г. с сайта https://www.tarleton.edu/academicassessment/documents/Samplesize.pdf.
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области. Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Насколько большой мне нужен образец?
Насколько большой мне нужен образец?Авторские права 20072020 Стэн Браун
Резюме: Когда вы оцениваете параметр населения, вы вычисляете доверительный интервал после взятия пробных данных. Основываясь на уверенности уровень, который вы предварительно выбрали, и характеристики вашего образца или населения, вычислите погрешность.Но , прежде чем проводить исследование, , как вы можете решить, насколько велик образец, который вам нужен, чтобы ваш доверительный интервал желаемая погрешность или меньше?
Ответ заключается в том, что вы берете формулу маржи ошибку, переставьте ее алгебраически на решить для размера выборки , вычислить и округлить . На этой странице показаны формулы для некоторых распространенных случаев с примерами.
См. Также:Если у вас TI-83 или TI-84, вы можете пропустить расчеты на этой веб-странице и загрузите программу для их выполнения. См. Программу MATh300A, часть 5.
Для более продвинутого лечения большего числа случаев:
Случай 0: одно среднее значение для популяции, известно σ
Если известно стандартное отклонение σ населения, и вы хотите оценить среднее значение μ с точностью до заданного Предел погрешности E в доверительном интервале 1-α, здесь как найти требуемый объем выборки n :
E = z α / 2 σ / √ п превращается в n = ( z α / 2 σ / E )
Пример 1: Вы хотите оценить среднюю почасовую производительность машина с точностью до 1.5, с достоверностью 90%. На основе исторические данные, у вас есть основания полагать, что стандарт отклонение почасовой производительности станков — 6,2. Насколько велик образец вам нужен?
Решение: Сначала обратите внимание, что это нереальная ситуация. Маловероятно, что вы будет знать стандартное отклонение населения, но не знать среднее значение этого населения. Однако тексты статистики всегда начинаются с в этом случае, потому что это самый простой способ продемонстрировать принципы.Вы покидаете Perfectland и попадаете в Realityville в другом случаи. С учетом сказанного
| Комментарии | Расчет |
|---|---|
| Хорошая практика — начинать любую проблему с записывать то, что вы знаете и что вам нужно, с помощью символов. | Дано: E = 1,5,
σ = 6,2, 1 − α = 0,90. Требуется: размер выборки n |
| Формула требует z α / 2 .Как это вычислить? Начнем с нахождения α / 2. | 1 − α = 0,90 ⇒
α = 0,10 ⇒
α / 2 = 0,05 Поскольку α / 2 = 0,05, z α / 2 = z 0,05 |
z rtail является критический z , или оценка z , которая делит нормальную кривую
оставляя правый хвост площадью rtail . Вы вычислите это
на вашем TI-83/84/89 как invNorm (1- rtail ) . | z 0,05 = invNorm (1−0,05) ≈ 1,6449 |
Теперь у вас есть все части. Не используйте
округленное значение z α / 2 , но используйте [ 2nd (-) делает ANS ], чтобы сохранить
полная точность. | n = [ z α / 2 σ E ] = (ANS6.21.5) = 46,2227 … → 47 |
Ответ: Учитывая стандартное отклонение совокупности 6.2 единиц в час, если у вас размер выборки ≥47 маржа ошибки в 90% доверительном интервале будет ≤1,5 единиц на час.
Почему мы округляем? После вычисления 46.2227, почему бы не сообщить размер выборки 46? Что ж, расчет показывает, что размер выборки ровно 46,2227 … даст маржу в размере погрешность ровно 1,5. Если вы опуститесь немного ниже, до 46, запас погрешность будет чуть выше 1,5. Поскольку размер выборки должен быть целое число, 46 или 47, и ваша погрешность не должна превышать 1.5, вы должны выбрать немного большее число 47, что даст погрешность чуть меньше 1,5.
Случай 1: одно среднее значение по совокупности, неизвестно σ
Примечание: Многие курсы базовой статистики пропускают материал в этом разделе и оценить размер выборки используя распределение z , поэтому материал в этом разделе может быть дополнительные возможности для вас. Проверьте требования к вашему курсу.
Это реалистичный случай для оценки популяции иметь в виду.Обычно вы не знаете стандартного отклонения население, поэтому вы должны использовать Распределение студентов t вместо нормального (z) распределения. Вы оцениваете стандартное отклонение совокупности от стандартное отклонение образца, полученного в предыдущем исследовании, или небольшое обучение пилота. Вот формула для размера выборки:
E = t df , α / 2 s / √ n превращается в n = t df , α / 2 s / E )
В этой формуле есть определенный элемент Уловки-22. для n .Вы не знаете n , поэтому вы не знаете степени свободы df либо, и вы не можете вычислить критическое т для формулы. Как это обойти?
Используйте то, что NIST / SEMATECH называет итерационным методом . Сначала вычислите формулу, используя z α / 2 вместо т df , α / 2 . Потом, когда у вас есть предварительный размер выборки , определяемый (ab) используя таким образом z , пересчитайте формулу, используя этот размер выборки минус 1 для df .Эти два числа не должны сильно отличаться, так как t в целом не сильно отличается от z ; но если они есть, вы можно использовать второе число, чтобы еще раз вычислить t .
Внимание : Может случиться так, что формула дает размер выборки меньше 30. Но помните, что размер вашей выборки всегда должно быть не менее 30, если у вас нет веских оснований полагать, что основная популяция распределена нормально.
См. Также: Требуемые размеры образцов в электронном справочнике NIST / SEMATECH по статистике Методы : прокрутите вниз до раздела «Чаще мы» должен рассчитать размер выборки со стандартным отклонением генеральной совокупности быть неизвестным
Проиллюстрируем метод, используя модифицированную форму предыдущий пример.
Пример 2: Вы хотите оценить среднюю почасовую производительность машина с точностью до 1,5, с уверенностью 90%. А Небольшое пилотное исследование находит образец стандарта отклонение почасовой производительности станков — 6,2. Насколько велик образец вам нужен?
Решение: Используйте z вместо t для предварительной оценка, затем пересчитайте с t .
| Комментарии | Расчет |
|---|---|
| Маршалировать ваши данные. | Дано: E = 1,5, с = 6,2, 1 − α = 0,90. Требуется: размер выборки n |
| Формула требует t df , α / 2 , но мы приближаемся с z α / 2 . Начнем с нахождения α / 2. | 1 − α = 0,90 ⇒
α = 0,10 ⇒
α / 2 = 0,05 Поскольку α / 2 = 0,05, z α / 2 = z 0,05 |
| z 0.05 — критический z-показатель, который делит нормальный такое распределение, что площадь правого хвоста равна 0,05, и следовательно, площадь левого хвоста составляет 1-0,05. | z 0,05 = invNorm (1−0,05) ≈ 1,6449 |
Теперь у вас есть все детали, необходимые для предварительной
размер образца. Не используйте
округленное значение z α / 2 , но используйте [ 2nd (-) делает ANS ], чтобы сохранить
полная точность. | n = [ z α / 2 s E ] = (ANS6.21.5) = 46,2227 … → 47 |
Ваш предварительный размер выборки 47, и затем вы используете его для
вычислить t . df = n −1 = 46, поэтому вам нужно т 46,0,05 . На TI-84 вы можете использовать invT функция. | т 46,0,05 = 1,67866 |
| Теперь пересчитайте формулу, используя значение t .Помни всегда круглая выборка вверх. | n = [ t df , α / 2 s E ] = (ANS6.21.5) = 48,142 … → 49 |
Ответ: Учитывая стандартное отклонение выборки 6,2 единиц в час, если размер выборки ≥ 49 , маржа ошибки в 90% доверительном интервале будет ≤1,5 единиц на час.
Примечание: Размер выборки 49 немного больше, чем Случай 0 размер выборки 47.Это имеет смысл. Когда ты не знаешь стандартное отклонение совокупности, вы должны использовать t распределение. Студенты t более разбросаны, чем z, поэтому доверительные интервалы немного шире, поэтому вам нужно использовать более крупную выборку чтобы доверительный интервал оставался той же ширины.
Случай 2: Одна доля населения
Для биномиальных данных с истинной пропорцией p , совокупность стандартное отклонение σ = √ p (1- p ). Даже если вы не знаете p , значение p (1- p̂ ) из вашей выборки или вашей предыдущей оценки, если у вас нет образца будет близок к истинному значение p (1- p ) в генеральной совокупности, потому что произведение p (1- p ) не меняется так же сильно, как p меняется.
Замена p на p̂ в формуле может показаться вроде жульничества, но в данном случае это не так, потому что p (1- p ) меняется намного меньше, чем p сам по себе. Например, предположим, что истинная доля населения составляет 45%, но ваша оценка 35%. Истинное значение p (1- p ) составляет 0,450,55 = 0,2475, и ваша оценка составляет 0,350,65 = 0,2275. Разница между 0,2475 а 0,2275 намного меньше разницы между 0,45 и 0.35.
Следовательно, вы можете использовать функцию z , а формулы являются то же, что и в случае 0 с √ p̂ (1- p̂ ) заменено на σ:
E = z α / 2 √ p̂ (1- p̂ ) / n превращается в n = ( z α / 2 / E ) p̂ (1- p̂ )
Если у вас нет образца или какой-либо достоверной оценки, используйте p = (1- p̂ ) = 0.5. Это консервативная процедура , потому что произведение p̂ (1- p̂ ) принимает максимальное значение, когда p̂ = 0,5. Консервативный процедура может дать вам размер выборки больше, чем необходимо, но вы можете убедитесь, что ваш образец не будет слишком маленьким, что заставит вас выбросить ваш опрос и начните заново.
Осторожно : Образец не должен превышать 10% от Население. Другой способ взглянуть на это — 10-кратный размер выборки должен быть меньше или равен численности населения.
Пример 3: Какой процент избирателей проголосовал бы за вашу кандидат, если бы выборы прошли сегодня? Вы хотите 95% уверенности в Ваш ответ, с погрешностью не более 3,5%. Последний месячный опрос показал, что ваш кандидат получил поддержку 42%. Сколько избирателей нужно опросить?
| Комментарии | Расчет |
|---|---|
| Маршалировать ваши данные. Осторожность! 3,5% это 0,035, а не 0,35. | Дано: 1 − α = 0.95, E = 0,035, p̂ = 0,42 Требуются: размер выборки n |
| Чтобы найти z α / 2 , сначала найдите α / 2. | 1 − α = 0,95 ⇒ α = 0,05 ⇒ α / 2 = 0,025 |
| z α / 2 = z 0,025 , критическое z для правого площадь хвоста 0,025. Это invNorm (1 − 0,025). | |
Разделите на E и возведите в квадрат.Ты собираешься расчетов цепи , чтобы вам не приходилось повторно вводить
любой из ваших промежуточных номеров. Нажмите [/] и обратите внимание, как
калькулятор отвечает и , чтобы вы знали
используя предыдущий ответ. Введите 0,035 для E и нажмите [ ENTER ]; что дает вам результат дроби. Нажмите
[ x ] [ ENTER ], чтобы выровнять квадрат. | |
| Последнее звено в цепочке умножается на p̂ , а затем на (1− стр. ).Ваш результат 764. Помни всегда округлить размер выборки в большую сторону, независимо от десятичной дроби часть. |
Ответ: Чтобы найти 95% доверительный интервал с погрешностью нет более 3,5 процентных пунктов, где истинное население доля составляет около 42%, необходимо опросить не менее 764 человек .
10764 = 7640; предположительно электорат больше, чем это.
Пример 4: Предположим, вы планируете свой первый опрос и вы не имеете представления об уровне поддержки ваших кандидатов.Насколько большой образец нужно ли вам быть уверенным в погрешности не более 3,5% при 95% доверительном интервале?
Решение: Вычислить z α / 2 = 1.9600 как в предыдущем примере. Но на этот раз используйте p̂ = 0,5, поскольку у вас нет оценки для p .
n = ( z α / 2 E ) p̂ (1- p̂ ) = (invNorm (1-.025) /. 035) 0,42 (1−0,42) = 783,971 … → 784
Ответ: Чтобы найти 95% доверительный интервал с допустимой погрешностью, нет более 3-х.5 процентных пунктов, когда вы понятия не имеете истинная доля населения, вы должны опросить не менее 784 человек .
Случай 5: Разница двух пропорций населения
Когда вы сравниваете две пропорции населения, совершенно законно иметь образцы разного размера. В формула погрешности внизу слева — это просто расширение формула для одной доли населения.
Но когда вы планируете размер выборки, вы не можете решить одно уравнение для двух переменных n 1 и n 2 .(Если у вас была причина выбрать какое-то конкретное значение для одного из них, вы можете решить для другого.) Вы можете решить для размера выборки, если вы решили использовать один и тот же размер для обоих образцов.
превращается в
n = n 1 = n 2 =
[ p 1 (1− p 1 ) + p 2 (1− p̂ 2 )] ( z α / 2 / E )
По указанным выше причинам, если вы иметь какие-либо предварительные оценки доли населения p 1 и p 2 вы должны их использовать; в противном случае используйте 0.5.
Пример 5: Вы хотите знать, как ваши кандидаты поддержка различается между мужчинами и женщинами. Вы знаете, что общая поддержка составляет 42%. Сколько представителей каждого пола вы должны опрос, чтобы ответить на вопрос с уверенностью 90% и запасом погрешность не более 3%?
| Комментарии | Расчет |
|---|---|
| Маршалировать ваши данные. (Внимание! 3% — это 0,03, а не 0,3.) | Дано: 1 − α = 0,90, E = 0.03 Разыскиваются: размер выборки n = n 1 = n 2 |
| Есть ли у вас оценка p 1 и p 2 p 2 ? Да, поскольку общая поддержка составляет 42%, вы ожидаете, что мужские и женская поддержка не слишком отличается от этого. (Вы ожидаете, что p 1 и p 2 несколько отличаются, иначе вы бы не проводили опрос. Но помните из одна доля населения, которая не соответствует p (1- p ) сильно меняются, когда p меняется.) | Prior: p̂ 1 = 0,42 и
1− p̂ 1 = 0,58 p̂ 2 = 0,42 и 1− p̂ 2 = 0,58 |
| Вычислить z α / 2 обычным способом. | 1 − α = 0,90 ⇒
α = 0,10 ⇒ α / 2 = 0,05 z 0,05 = invNorm (1−0,05) ≈ 1,6449 |
| Завершите, используя неокругленное значение z . Всегда не забывай круглые размеры выборки вверх. | [ p 1 (1- p̂ 1 ) + p 2 (1- p̂ 2 )] [ z α / 2 E ] = (0,420,58 + 0,420,58) (ANS0,03) = 1464,60 … → 1465 |
Ответ: Чтобы найти 90% CI для разница в поддержке ваших кандидатов между мужчинами и женщинами, с погрешностью не более 3% необходимо обследование не менее 1465 мужчин и не менее 1465 женщин .
Реплика: Вы можете задаться вопросом, почему образцы должны быть такими? большой. Ведь для оценки одной популяции удельный вес в 3% при 90% доверительном интервале с априорной оценкой p̂ = 42% выборка из 752 достаточно. (Проверьте!) Зачем вам нужно более 2900 человек в двух группах для такая же погрешность?
Ответ в том, что это не та же погрешность. Если вы опросили 752 мужчины и 752 женщины, которым вы доверяете интервалы по 3% для каждого, но это общая маржа ошибки 6% считают, что истинная пропорция может быть в нижней части интервала одной группы и в верхней части интервала другие группы или наоборот.(Не все так просто, но это основная идея.) Чтобы уменьшить эту погрешность, вам необходимо увеличить размер выборки.
Пример 6: Давайте изменим предыдущий пример. Предположим, у вас есть основания верить своему кандидату больше нравится женщинам, с разрывом около 10%? Это означает вы оцениваете поддержку мужчин в 37% и женщин в 47%. p̂ 1 = 0,37, 1− p̂ 1 = 0,63, p̂ 2 = 0,47, 1− p̂ 2 = 0.52. Требуемый размер выборки становится
z 0,05 = invNorm (1−0,05) ≈ 1,6449
[ p 1 (1- p̂ 1 ) + p 2 (1- p̂ 2 )] [ z α / 2 E ] = (0,370,63 + 0,470,53) (ANS0,03) = 1449,57 … → 1450
Ответ: Для 90% доверительного интервала с погрешностью ≤3%, когда вы думаете, что одна популяционная доля составляет 37%, а другие — 47%, вам нужна выборка не менее 1450 из каждой группы .
Случай 6: Хорошая посадка
Требования к χ-тестам заключаются в следующем: все ожидаемые числа должны быть ≥5. Ожидаемое количество для каждой категории — размер выборки n раза пропорции модели в этой категории, чтобы найти необходимые размер выборки вы разделите это минимальное ожидаемое значение 5 на наименьшая доля или процент в модели:
n = 5 / (наименьшая пропорция в вашей модели)
Если ваша модель выражена в соотношениях, например 9: 3: 3: 1, наименьшая доля — наименьшее число в модели, деленное на всего в модели, в данном случае 1 / (9 + 3 + 3 + 1) или 1/16.Итак, необходимая размер выборки 5 / (1/16) = 80.
Пример 7: Вы ожидаете, что покупатели выберут кофе, чай, вода в бутылках и Snapple в пропорциях 65%, 15%, 15%, 5%. Какой размер случайной выборки нужно взять для тестирования этой модели?
Решение : Возьмите наименее вероятную категорию и разделите 5 на этот процент:
n = 5/5% = 5 / 0,05 = 100.
Ответ : Вам нужна случайная выборка не менее 100 для тестирования этой модели.(Как всегда, минимум выборка даст значимый результат, только если нулевая гипотеза крайне неправильно. Если модель ошибочна лишь в некоторой степени, большее для этого, вероятно, потребуется образец.)
Пример 8: Для детской игровой площадки вы заказали пять коробок. из синих пластиковых шаров, два зеленых и по три красных и желтых. Но ваш помощник выбросил их все вместе после доставки. Как много шаров нужно выбрать случайным образом, чтобы проверить, соответствуют ли пропорции верно?
Решение : Вы должны разделить 5 на пропорцию в наименьшая категория в модели, зеленая:
наименьшая доля = 2 / (5 + 2 + 3 + 3) = 2/13
5 / (2/13) = 32.5 → 33
Ответ : Для выполнения требований необходим случайный образец не менее 33 мячей .
Пример 9: Вы полагаете, что простые сделки M&M распространяются в пропорции 24% синий, 13% коричневый, 16% зеленый, 18% оранжевый, 15% красный, 14% желтый. Как большой образец нужен ли вам для тестирования этой модели?
Решение : Наименьшая доля в модели составляет 13%, поэтому вычислите 5/13% = 5 / 0,13 = 38,46 … → 39. (Помните, что размер выборки всегда округляется.)
Ответ : Образец должен содержать не менее 39 M & Ms.
Что нового
- 24 октября 2020 г. : преобразование HTML 4.01 в HTML5. Выделить переменную курсивом имена. Улучшение форматирования радикалов. Заменить картинки большинства уравнений с теми же уравнениями в текстовой форме.
- 24 августа 2013 г. : изменить формулу для случая 2 для упрощения вычислений. Измените требования с ≤5% на ≤10% населения. Изменить регистр 6 требования, запрещающие любые ожидаемые значения ниже 5, что исключает под-кейсы.
- 1 января 2013 г. : Добавить Случай 6: Доброта Соответствовать.
- (промежуточные изменения подавлены)
- Осень 2007 г. : Новая статья.
Глава 10 Оценка неизвестных величин по выборке
Во всех примерах IQ в предыдущих разделах мы фактически знали параметры генеральной совокупности заранее. Поскольку каждый студент на своей самой первой лекции по измерению интеллекта проходит курс обучения, показатель IQ составляет баллов, при этом баллов имеют среднее значение 100 и стандартное отклонение 15.Однако это немного ложь. Как мы узнаем, что истинное среднее значение IQ равно 100? Что ж, мы знаем это, потому что люди, которые разработали тесты, проводили их с очень большими выборками, а затем «подстроили» правила подсчета так, чтобы их выборка имела среднее значение 100. Это, конечно, неплохо: это важная часть разработка психологического измерения. Однако важно помнить, что это теоретическое среднее значение 100 относится только к совокупности, которую разработчики тестов использовали для разработки тестов.Хорошие разработчики тестов на самом деле пойдут на многое, чтобы предоставить «нормы тестирования», которые могут применяться ко множеству разных групп населения (например, разных возрастных групп, национальностей и т. Д.).
Это очень удобно, но, конечно же, почти каждый интересующий исследовательский проект включает изучение популяции людей, отличных от тех, которые используются в нормах тестирования. Например, предположим, что вы хотите измерить эффект отравления свинцом низкой концентрации на когнитивные функции в Порт-Пири, промышленном городе Южной Австралии, где есть свинцовый завод.Возможно, вы решите сравнить показатели IQ людей в Порт-Пири с сопоставимой выборкой в Уайалле, промышленном городке в Южной Австралии, где расположен сталелитейный завод. Независимо от того, о каком городе вы думаете, не имеет большого смысла просто предполагать , что истинный средний IQ населения равен 100. Насколько мне известно, никто не предоставил разумных нормирующих данных, которые можно было бы автоматически определить. применяется к промышленным городам Южной Австралии. Нам нужно будет оценить параметров генеральной совокупности на основе выборки данных.Итак, как мы это сделаем?
Оценка среднего населения
Предположим, мы едем в Порт Пири, и 100 местных жителей достаточно любезны, чтобы пройти тест на IQ. Средний показатель IQ среди этих людей оказался \ (\ bar {X} = 98,5 \). Итак, каков истинный средний IQ для всего населения Порт-Пири? Очевидно, мы не знаем ответа на этот вопрос. Это может быть \ (97,2 \), но если также может быть \ (103,5 \). Наша выборка не является исчерпывающей, поэтому мы не можем дать окончательный ответ. Тем не менее, если бы меня под дулом пистолета заставили дать «лучшее предположение», я бы сказал: \ (98.5 \). В этом суть статистической оценки: дать наилучшее предположение.
В этом примере оценить неизвестный параметр разрастания несложно. Я вычисляю выборочное среднее и использую его в качестве оценки среднего для генеральной совокупности . Это довольно просто, и в следующем разделе я объясню статистическое обоснование этого интуитивного ответа. Однако на данный момент я хочу убедиться, что вы осознаете, что статистика выборки и оценка параметра совокупности концептуально разные вещи.Выборочная статистика — это описание ваших данных, тогда как оценка — это предположение о генеральной совокупности. Имея это в виду, статистики часто используют разные обозначения для их обозначения. Например, если истинное среднее значение совокупности обозначено \ (\ mu \), то мы будем использовать \ (\ hat \ mu \) для обозначения нашей оценки среднего значения совокупности. Напротив, выборочное среднее обозначается \ (\ bar {X} \) или иногда \ (m \). Однако в простых случайных выборках оценка среднего генеральной совокупности идентична выборочному среднему: если я наблюдаю выборочное среднее значение \ (\ bar {X} = 98.5 \), то моя оценка среднего населения также равна \ (\ hat \ mu = 98,5 \). Вот удобная таблица, чтобы упростить обозначения:
knitr :: kable (data.frame (stringsAsFactors = ЛОЖЬ,
Symbol = c ("$ \\ bar {X} $", "$ \\ mu $", "$ \\ hat {\\ mu} $"),
What.is.it = c («Среднее значение выборки», «Истинное среднее значение генеральной совокупности»,
«Оценка среднего населения»),
Do.we.know.what.it.is = c ("Да, рассчитано по необработанным данным",
"Почти никогда не известно наверняка",
«Да идентично среднему образцу»))) | \ (\ bar {X} \) | Выборочное среднее | Да, рассчитано по необработанным данным |
| \ (\ му \) | Истинное среднее значение населения | Почти никогда не известно наверняка |
| \ (\ hat {\ mu} \) | Оценка среднего населения | Да, идентично выборочному среднему |
Оценка стандартного отклонения совокупности
Пока что оценка кажется довольно простой, и вам может быть интересно, почему я заставил вас прочитать все эти вещи о теории выборки.В случае среднего значения наша оценка параметра совокупности (то есть \ (\ hat \ mu \)) оказалась идентичной соответствующей статистике выборки (то есть \ (\ bar {X} \)). Однако это не всегда так. Чтобы убедиться в этом, давайте подумаем о том, как построить оценку стандартного отклонения совокупности , которую мы обозначим \ (\ hat \ sigma \). Что мы будем использовать в качестве оценки в этом случае? Ваша первая мысль может заключаться в том, что мы могли бы сделать то же самое, что и при оценке среднего, и просто использовать статистику выборки в качестве нашей оценки.Это почти то, что нужно сделать, но не совсем.
Вот почему. Предположим, у меня есть образец, содержащий одно наблюдение. В этом примере полезно рассмотреть выборку, в которой у вас нет никаких предположений о том, какими могут быть истинные значения генеральной совокупности, поэтому давайте воспользуемся чем-нибудь полностью вымышленным. Предположим, что рассматриваемое наблюдение измеряет цветность моей обуви и . Оказалось, что у моих туфель цветность 20. Итак, вот мой образец:
20 Это вполне законная выборка, даже если ее размер составляет \ (N = 1 \).Он имеет выборочное среднее 20, и поскольку каждое наблюдение в этой выборке равно выборочному среднему (очевидно!), У него есть стандартное отклонение выборки, равное 0. В качестве описания образца это кажется вполне правильным: образец содержит единичное наблюдение, и, следовательно, в выборке не наблюдается никаких изменений. Пример стандартного отклонения \ (s = 0 \) — правильный ответ. Но как оценка стандартного отклонения населения в , это кажется совершенно безумным, не так ли? По общему признанию, мы с вами вообще ничего не знаем о том, что такое «cromulence», но мы кое-что знаем о данных: единственная причина, по которой мы не видим какой-либо изменчивости в выборке , заключается в том, что выборка слишком мала для отображать любые вариации! Итак, если у вас размер выборки \ (N = 1 \), воспринимается как , как будто правильный ответ — просто сказать «вообще не знаю».
Обратите внимание, что у вас, , нет такой же интуиции, когда дело касается выборочного среднего и генерального среднего. Если вы вынуждены делать наилучшее предположение о среднем населении, то не кажется совершенно безумным предположить, что среднее значение для населения равно 20. Конечно, вы, вероятно, не почувствуете себя очень уверенным в этом предположении, потому что у вас есть только одно наблюдение для работать, но это все равно лучшее предположение, которое вы можете сделать.
Давайте немного расширим этот пример. Предположим, я сделаю второе наблюдение.В моем наборе данных теперь есть \ (N = 2 \) наблюдений за цветностью обуви, и полная выборка теперь выглядит так:
20, 22 На этот раз наша выборка составляет , всего достаточно для того, чтобы мы могли наблюдать некоторую изменчивость: два наблюдения — это минимальное количество, необходимое для наблюдения любой изменчивости! Для нашего нового набора данных выборочное среднее равно \ (\ bar {X} = 21 \), а стандартное отклонение выборки равно \ (s = 1 \). Какое у нас представление о населении? Опять же, что касается среднего значения генеральной совокупности, лучшее предположение, которое мы можем сделать, — это выборочное среднее: если мы будем вынуждены предполагать, мы, вероятно, предположим, что средняя численность населения равна 21.А как насчет стандартного отклонения? Это немного сложнее. Стандартное отклонение выборки основано только на двух наблюдениях, и если вы вообще похожи на меня, у вас, вероятно, есть интуиция, что всего с двумя наблюдениями мы не дали населению «достаточно шансов» выявить его истинную изменчивость. нам. Дело не только в том, что мы подозреваем, что оценка неверна, : в конце концов, имея всего два наблюдения, мы ожидаем, что она в какой-то степени неверна. Беспокойство вызывает то, что ошибка — систематическая .В частности, мы подозреваем, что стандартное отклонение выборки, вероятно, будет меньше, чем стандартное отклонение генеральной совокупности.
Рисунок 10.11: Выборочное распределение стандартного отклонения выборки для эксперимента «два показателя IQ». Истинное стандартное отклонение совокупности составляет 15 (пунктирная линия), но, как вы можете видеть из гистограммы, подавляющее большинство экспериментов дадут гораздо меньшее стандартное отклонение выборки, чем это. В среднем, в этом эксперименте стандартное отклонение выборки будет всего 8.5, что значительно ниже истинного значения! Другими словами, стандартное отклонение выборки — это смещенная оценка стандартного отклонения генеральной совокупности.
Эта интуиция кажется правильной, но было бы неплохо как-то это продемонстрировать. На самом деле есть математические доказательства, подтверждающие эту интуицию, но если у вас нет правильного математического образования, они не очень помогают. Вместо этого я буду использовать R для моделирования результатов некоторых экспериментов. Имея это в виду, давайте вернемся к нашим исследованиям IQ.Предположим, что истинное среднее значение IQ в популяции равно 100, а стандартное отклонение — 15. Я могу использовать функцию rnorm () для получения результатов эксперимента, в котором я измеряю \ (N = 2 \) баллов IQ, и вычисляю стандартное отклонение выборки. Если я делаю это снова и снова и строю гистограмму этих стандартных отклонений выборки, то у меня получается распределение выборки для стандартного отклонения . Я изобразил это распределение на рис. 10.11. Несмотря на то, что истинное стандартное отклонение совокупности составляет 15, среднее значение стандартного отклонения выборки составляет всего 8.5. Обратите внимание, что это сильно отличается от того, что мы обнаружили на рис. 10.8, когда построили выборочное распределение среднего. Если вы посмотрите на это распределение выборки, то увидите, что среднее значение генеральной совокупности равно 100, и среднее значение выборки также равно 100.
Теперь давайте расширим симуляцию. Вместо того, чтобы ограничиваться ситуацией, когда размер выборки равен \ (N = 2 \), давайте повторим упражнение для размеров выборки от 1 до 10. Если мы построим среднее значение выборки и среднее стандартное отклонение выборки как функцию от размер выборки, вы получите результаты, показанные на рисунке 10.12. С левой стороны (панель a) я нанес среднее значение выборки, а с правой стороны (панель b) — среднее стандартное отклонение. Эти два графика сильно различаются: в среднем , , среднее значение выборки равно среднему значению генеральной совокупности. Это несмещенная оценка , что, по сути, является причиной того, почему ваша лучшая оценка для среднего значения генеральной совокупности является выборочным средним. График справа совершенно другой: в среднем стандартное отклонение выборки \ (s \) на меньше на , чем стандартное отклонение генеральной совокупности \ (\ sigma \).Это смещенная оценка . Другими словами, если мы хотим сделать «наилучшее предположение» \ (\ hat \ sigma \) о значении стандартного отклонения совокупности \ (\ sigma \), мы должны убедиться, что наше предположение немного больше, чем стандартное отклонение выборки \ (s \).
Рисунок 10.12: Иллюстрация того факта, что среднее по выборке является несмещенной оценкой среднего значения генеральной совокупности (панель a), а стандартное отклонение выборки является смещенной оценкой стандартного отклонения совокупности (панель b).Чтобы получить цифру, я сгенерировал 10 000 смоделированных наборов данных с 1 наблюдением в каждом, еще 10 000 с 2 наблюдениями и так далее до размера выборки 10. Каждый набор данных состоял из поддельных данных IQ: то есть данные были нормально распределены. при истинном среднем генеральной совокупности 100 и стандартном отклонении 15. В среднем средние значения выборки оказываются равными 100, независимо от размера выборки (панель a). Однако стандартные отклонения выборки оказываются систематически слишком малыми (панель b), особенно для малых размеров выборки.2}
\], а когда мы используем встроенную в R функцию стандартного отклонения sd () , она вычисляет \ (\ hat \ sigma \), а не \ (s \).
И последнее замечание: на практике многие люди склонны ссылаться на \ (\ hat {\ sigma} \) (т.е. формулу, в которой мы делим на \ (N-1 \)) как на стандартное отклонение образца . . Технически это неверно: стандартное отклонение выборки должно быть равно \ (s \) (то есть формуле, в которой мы делим на \ (N \)). Это не одно и то же ни концептуально, ни численно.Одно — свойство выборки, другое — оценочная характеристика совокупности. Однако почти в каждом реальном приложении нас действительно волнует оценка параметра численности, поэтому люди всегда сообщают \ (\ hat \ sigma \), а не \ (s \). Это правильное число, чтобы сообщить, конечно, потому что люди имеют тенденцию быть немного неточными в терминологии, когда они ее записывают, потому что «стандартное отклонение выборки» короче, чем «оценочное стандартное отклонение совокупности».В этом нет ничего страшного, и на практике я делаю то же, что и все остальные. Тем не менее, я думаю, что важно разделять две концепции : никогда не стоит путать «известные свойства вашей выборки» с «предположениями о популяции, из которой она произошла». В тот момент, когда вы начинаете думать, что \ (s \) и \ (\ hat \ sigma \) — это одно и то же, вы начинаете делать именно это.
Чтобы завершить этот раздел, вот еще пара таблиц, которые помогут прояснить ситуацию:
knitr :: kable (данные.2 $ "),
What.is.it = c ("Стандартное отклонение выборки",
«Стандартное отклонение населения»,
«Оценка стандартного отклонения генеральной совокупности», «Дисперсия выборки»,
«Дисперсия населения»,
«Оценка дисперсии генеральной совокупности»),
Do.we.know.what.it.is = c ("Да - рассчитано по необработанным данным",
"Почти никогда не известно наверняка",
«Да, но не то же самое, что стандартное отклонение выборки»,
«Да - рассчитано по необработанным данным»,
"Почти никогда не известно наверняка",
«Да - но не то же самое, что и выборочная дисперсия»)
)) | \ (с \) | Стандартное отклонение выборки | Да — рассчитано по необработанным данным |
| \ (\ sigma \) | Стандартное отклонение населения | Почти никогда не известно наверняка |
| \ (\ hat {\ sigma} \) | Оценка стандартного отклонения населения | Да, но не то же самое, что стандартное отклонение выборки |
| \ (s ^ 2 \) | Вариант выборки | Да — рассчитано по необработанным данным |
| \ (\ sigma ^ 2 \) | Дисперсия населения | Почти никогда не известно наверняка |
| \ (\ hat {\ sigma} ^ 2 \) | Оценка дисперсии совокупности | Да, но не то же самое, что и выборочная дисперсия |
6.2: Выборочное распределение выборочных средних
Чтобы увидеть, как мы используем ошибку выборки, мы узнаем о новом теоретическом распределении, известном как выборочное распределение. Точно так же, как мы можем собрать множество индивидуальных оценок и сложить их вместе, чтобы сформировать распределение с центром и разбросом, если бы мы взяли много выборок, все одного размера, и вычислили среднее значение каждой из них, мы могли бы собрать эти средства вместе, чтобы сформировать дистрибутив. Это новое распределение интуитивно известно как распределение выборочных средних.Это один из примеров того, что мы называем выборочным распределением, мы можем быть сформированы из набора любой статистики, такой как среднее значение, тестовая статистика или коэффициент корреляции (подробнее о последних двух в блоках 2 и 3). Для наших целей понимания распределения выборочных средних будет достаточно, чтобы увидеть, как работают все другие выборочные распределения, чтобы обеспечить и информировать наш выводный анализ, поэтому эти два термина будут использоваться как взаимозаменяемые с этого момента. Давайте подробнее рассмотрим некоторые из его характеристик.
Выборочное распределение выборочных средних может быть описано его формой, центром и размахом, как и любое другое распределение, с которым мы работали. Форма нашего выборочного распределения нормальная: колоколообразная кривая с одним пиком и двумя хвостами, симметрично вытянутыми в обоих направлениях, как и то, что мы видели в предыдущих главах. Центр выборочного распределения выборочных средних — который сам по себе является средним или средним из средних — является истинным средним по генеральной совокупности, \ (μ \).Иногда это будет записываться как \ (\ mu _ {\ overline {X}} \), чтобы обозначить это как среднее из выборочных средних. Разброс распределения выборки называется стандартной ошибкой, количественной оценкой ошибки выборки, обозначаемой \ (\ mu _ {\ overline {X}} \). Формула стандартной ошибки:
\ [\ sigma _ {\ overline {X}} = \ dfrac {\ sigma} {\ sqrt {n}} \]
Обратите внимание, что в этом уравнении указан размер выборки. Как указано выше, распределение выборки относится к выборкам определенного размера. То есть все средние выборки должны быть рассчитаны на основе выборок одинакового размера \ (n \), например \ (n \) = 10, \ (n \) = 30 или \ (n \) = 100.Этот размер выборки относится к количеству людей или наблюдений в каждой отдельной выборке, а не к количеству выборок, используемых для формирования выборочного распределения. Это связано с тем, что выборочное распределение является теоретическим распределением, которое мы никогда не будем вычислять или наблюдать. Рисунок \ (\ PageIndex {1} \) отображает изложенные здесь принципы в графической форме.
Рисунок \ (\ PageIndex {1} \): распределение выборки означаетДве важные аксиомы
Мы только что узнали, что распределение выборки является теоретическим: мы никогда его не видим.Если это правда, то как мы можем узнать, что это работает? Как мы можем использовать то, чего не видим? Ответ кроется в двух очень важных математических фактах: центральной предельной теореме и законе больших чисел. {2}} {n} \).Это распределение будет приближаться к нормальному при увеличении \ (n \).
Отсюда мы можем найти стандартное отклонение нашего выборочного распределения, стандартную ошибку. Как видите, как и любое другое стандартное отклонение, стандартная ошибка — это просто квадратный корень из дисперсии распределения.
Последнее предложение центральной предельной теоремы гласит, что распределение выборки будет нормальным по мере увеличения размера выборки, используемой для его создания. Это означает, что более крупные выборки создадут более нормальное распределение, поэтому мы сможем лучше использовать методы, которые мы разработали для нормальных распределений и вероятностей.Так насколько большой достаточно большой? В общем случае выборочное распределение будет нормальным, если верна одна из двух характеристик:
- совокупность, из которой отбираются образцы, имеет нормальное распределение или
- размер выборки равен или больше 30.
Этот второй критерий очень важен, потому что он позволяет нам использовать методы, разработанные для нормального распределения, даже если истинное распределение населения искажено.
Закон больших чисел
Закон больших чисел просто гласит, что по мере увеличения размера нашей выборки вероятность того, что наше среднее значение по выборке является точным представлением истинного среднего значения по генеральной совокупности, также увеличивается.Это формальный математический способ заявить, что более крупные образцы более точны.
Закон больших чисел связан с центральной предельной теоремой, а именно с формулами для дисперсии и стандартной ошибки. Обратите внимание, что размер выборки указан в знаменателях этих формул. Больший знаменатель в любой дроби означает, что общее значение дроби становится меньше (например, 1/2 = 0,50, 1/3 — 0,33, 1/4 = 0,25 и т. Д.). Таким образом, большие размеры выборки создадут меньшие стандартные ошибки.Мы уже знаем, что стандартная ошибка — это разброс выборочного распределения, а меньший разброс создает более узкое распределение. Следовательно, большие размеры выборки создают более узкие распределения выборки, что увеличивает вероятность того, что среднее значение выборки будет близко к центру, и снижает вероятность того, что оно окажется в хвосте. Это показано на рисунках \ (\ PageIndex {2} \) и \ (\ PageIndex {3} \).
Рисунок \ (\ PageIndex {2} \): распределения выборки из одной и той же генеральной совокупности с \ (μ \) = 50 и \ (σ \) = 10, но разными размерами выборки (\ (N \) = 10, \ (N \ ) = 30, \ (N \) = 50, \ (N \) = 100) Рисунок \ (\ PageIndex {3} \): соотношение между размером выборки и стандартной ошибкой для константы \ (σ \) = 10авторов. и атрибуция
Foster et al.(Университет Миссури — Сент-Луис, Университет Райса и Университет Хьюстона, кампус в центре города)
Формулы стандартного отклонения
Отклонение просто означает, насколько далеко от нормы
Стандартное отклонениеСтандартное отклонение — это мера , насколько разброс наши номера .
Вы можете сначала прочитать эту более простую страницу о стандартном отклонении.
Но здесь мы объясняем формулы .
Символ стандартного отклонения — σ (греческая буква сигма).
Это формула для стандартного отклонения:
Сказать что? Объясните, пожалуйста!
ОК. Давайте объясним это шаг за шагом.
Допустим, у нас есть набор чисел вроде 9, 2, 5, 4, 12, 7, 8, 11.
Чтобы вычислить стандартное отклонение этих чисел:
- 1. Определите среднее (простое среднее номеров)
- 2.Затем для каждого числа: вычтите Среднее и возведите результат в квадрат
- 3. Затем вычислите среднее значение этих квадратов разностей .
- 4. Извлеките из этого квадратный корень, и все готово!
Формула действительно говорит обо всем этом, и я покажу вам, как это сделать.
Объяснение формулы
Во-первых, у нас есть несколько примеров значений для работы:
Пример: У Сэма 20 кустов роз.
Количество цветков на каждом кусте
9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4
Определите стандартное отклонение.
Шаг 1. Определите среднее значение
В приведенной выше формуле μ (греческая буква «мю») — это среднее всех наших значений …
Пример: 9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4
Среднее значение:
9 + 2 + 5 + 4 + 12 + 7 + 8 + 11 + 9 + 3 + 7 + 4 + 12 + 5 + 4 + 10 + 9 + 6 + 9 + 4 20
= 140 20 = 7
Итак:
мк = 7
Шаг 2.Затем для каждого числа: вычтите Среднее и возведите результат в квадрат
Это часть формулы, которая гласит:
Так что же такое x i ? Это отдельные значения x 9, 2, 5, 4, 12, 7 и т.д …
Другими словами x 1 = 9, x 2 = 2, x 3 = 5 и т. Д.
Итак, здесь говорится: «для каждого значения вычтите среднее и возведите результат в квадрат», например,
Пример (продолжение):
(9-7) 2 = (2) 2 = 4
(2-7) 2 = (-5) 2 = 25
(5-7) 2 = (-2) 2 = 4
(4-7) 2 = (-3) 2 = 9
(12-7) 2 = (5) 2 = 25
(7-7) 2 = (0) 2 = 0
(8–7) 2 = (1) 2 = 1
… и т.д …
И получаем следующие результаты:
4, 25, 4, 9, 25, 0, 1, 16, 4, 16, 0, 9, 25, 4, 9, 9, 4, 1, 4, 9
Шаг 3. Затем вычислите среднее значение квадратов разностей.
Чтобы вычислить среднее значение, сложите все значения , затем разделите на количество .
Сначала сложите все значения из предыдущего шага.
Но как сказать в математике «сложить все»? Используем «Сигма»: Σ
Удобная сигма-нотация позволяет суммировать столько терминов, сколько мы хотим:
Сигма-нотация
Мы хотим сложить все значения от 1 до N, где в нашем случае N = 20, потому что имеется 20 значений:
Пример (продолжение):
Это означает: суммировать все значения от (x 1 -7) 2 до (x N -7) 2
Мы уже вычислили (x 1 -7) 2 = 4 и т. Д.на предыдущем шаге, так что просто суммируйте их:
= 4 + 25 + 4 + 9 + 25 + 0 + 1 + 16 + 4 + 16 + 0 + 9 + 25 + 4 + 9 + 9 + 4 + 1 + 4 + 9 = 178
Но это еще не среднее значение, нам нужно разделить на сколько , что делается путем умножения на 1 / N (то же самое, что деление на N):
Пример (продолжение):
Среднее значение квадратов разностей = (1/20) × 178 = 8,9
(Примечание: это значение называется «Дисперсия»)
Шаг 4.Извлеките квадратный корень из этого:
Пример (заключение):
σ = √ (8,9) = 2,983 …
СДЕЛАНО!
Стандартное отклонение выборки
Но подождите, это еще не все …
… иногда наши данные — это всего лишь выборка всего населения.
Пример: У Сэма
20 кустов роз , но посчитал цветов только на 6 из них !«Население» — это всего 20 кустов роз,
, а «образец» — это 6 кустов, цветы которых Сэм считал.
Допустим, у Сэма количество цветов:
9, 2, 5, 4, 12, 7
Мы все еще можем оценить стандартное отклонение.
Но когда мы используем выборку в качестве оценки для всей генеральной совокупности , формула стандартного отклонения меняется на это:
Формула для Стандартное отклонение выборки :
Важным изменением является «N-1» вместо «N» (что называется «поправкой Бесселя»).
Символы также меняются, чтобы отразить, что мы работаем с выборкой, а не со всей генеральной совокупностью:
- Среднее значение теперь x (для выборочного среднего) вместо μ (среднее для генеральной совокупности),
- И ответ: s (для стандартного отклонения выборки) вместо σ .
Но это не влияет на расчеты. Только N-1 вместо N меняет вычисления.
Хорошо, давайте теперь вычислим стандартное отклонение выборки :
Шаг 1.Вычислить среднее значение
Пример 2: Использование значений выборки 9, 2, 5, 4, 12, 7
Среднее значение: (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39/6 = 6,5
Итак:
х = 6,5
Шаг 2. Затем для каждого числа: вычтите Среднее и возведите результат в квадрат
Пример 2 (продолжение):
(9 — 6,5) 2 = (2,5) 2 = 6,25
(2 — 6,5) 2 = (-4,5) 2 = 20,25
(5 — 6,5) 2 = (-1.5) 2 = 2,25
(4 — 6,5) 2 = (-2,5) 2 = 6,25
(12 — 6,5) 2 = (5,5) 2 = 30,25
(7 — 6,5) 2 = (0,5) 2 = 0,25
Шаг 3. Затем вычислите среднее значение квадратов разностей.
Чтобы вычислить среднее значение, сложите все значения , затем разделите на количество .
Но подождите … мы вычисляем стандартное отклонение Sample , поэтому вместо деления на количество (N) мы разделим на N-1
Пример 2 (продолжение):
Сумма = 6.25 + 20,25 + 2,25 + 6,25 + 30,25 + 0,25 = 65,5
Разделить на N-1 : (1/5) × 65,5 = 13,1
(Это значение называется «Выборочная дисперсия»)
Шаг 4. Извлеките квадратный корень из этого:
Пример 2 (завершение):
с = √ (13,1) = 3,619 …
СДЕЛАНО!
Сравнение
Когда мы использовали всю совокупность , мы получили: Среднее = 7 , Стандартное отклонение = 2.983 …
Когда мы использовали образец , мы получили: среднее значение выборки = 6,5 , стандартное отклонение выборки = 3,619 …
Наше выборочное среднее было неверным на 7%, а наше стандартное отклонение выборки было неверным на 21%.
Зачем нужно брать образец?
В основном потому, что так проще и дешевле.
Представьте, что вы хотите знать, что думает вся страна … вы не можете спрашивать миллионы людей, поэтому вместо этого вы спрашиваете, может быть, 1000 человек.
Есть хорошая цитата (возможно, Самуэль Джонсон):
«Не обязательно есть животное целиком, чтобы знать, что мясо жесткое.»
Это основная идея отбора проб. Чтобы получить информацию о совокупности (такую как среднее значение и стандартное отклонение), нам не нужно смотреть на всех членов населения; нам нужен только образец.
Но когда мы берем образец, мы теряем некоторую точность.
Сводка
Население Стандартное отклонение: | ||
| Образец Стандартное отклонение: |
— уровень достоверности, доверительный интервал, размер выборки, размер совокупности, соответствующая совокупность
Калькулятор размера выборки представляет собой общедоступную услугу программного обеспечения для проведения опросов Creative Research Systems.Вы можете использовать его, чтобы определить, сколько людей вам нужно проинтервьюировать, чтобы получить результаты, отражающие целевую совокупность настолько точно, насколько это необходимо. Вы также можете найти уровень точности, который у вас есть в существующем образце.
Перед использованием калькулятора размера выборки вам необходимо знать два термина. Это: доверительный интервал и доверительный интервал . Если вы не знакомы с этими условиями, щелкните здесь. Чтобы узнать больше о факторах, влияющих на размер доверительных интервалов, щелкните здесь.
Введите свой выбор в калькулятор ниже, чтобы найти необходимый размер выборки или доверительный интервал. у тебя есть. Оставьте поле Население пустым, если популяция очень большая или неизвестна.
Термины калькулятора размера выборки: доверительный интервал и доверительный уровень
Доверительный интервал (также называемый пределом погрешности) — это положительное или отрицательное число, обычно указываемое в результатах газетных или телевизионных опросов.Например, если вы используете доверительный интервал 4 и 47% процентов вашей выборки выбирает ответ, вы можете быть «уверены», что если бы вы задали вопрос всей соответствующей совокупности, от 43% (47-4) до 51% (47 + 4) выбрали бы этот ответ.
Уровень достоверности говорит вам, насколько вы можете быть уверены. Он выражается в процентах и показывает, как часто истинный процент населения, которое выберет ответ, находится в пределах доверительного интервала. Уровень достоверности 95% означает, что вы можете быть уверены на 95%; Уровень достоверности 99% означает, что вы можете быть уверены на 99%.Большинство исследователей используют уровень достоверности 95%.
Если сложить доверительный интервал и доверительный интервал, можно сказать, что вы на 95% уверены, что истинный процент населения составляет от 43% до 51%. Чем шире доверительный интервал, который вы готовы принять, тем больше у вас будет уверенности в том, что ответы всего населения будут в пределах этого диапазона.
Например, если вы спросили у выборки из 1000 жителей города, какую марку колы они предпочитают, и 60% ответили маркой А, вы можете быть уверены, что от 40 до 80% всех жителей города действительно предпочитают этот бренд, но нельзя быть уверенным, что от 59 до 61% жителей города предпочитают этот бренд.
Факторы, влияющие на доверительные интервалы
Существует три фактора, которые определяют размер доверительного интервала для данного уровня достоверности:
- Объем выборки
- Процент
- Численность населения чел.
Размер выборки
Чем больше размер вашей выборки, тем больше вы можете быть уверены в том, что их ответы действительно отражают население. Это означает, что для данного уровня достоверности, чем больше размер вашей выборки, тем меньше доверительный интервал.Однако эта зависимость не является линейной (, то есть , удвоение размера выборки не уменьшает вдвое доверительный интервал).
Процент
Ваша точность также зависит от процента вашей выборки, которая выбирает конкретный ответ. Если 99% вашей выборки ответили «Да», а 1% — «Нет», вероятность ошибки мала, независимо от размера выборки. Однако, если процентные значения составляют 51% и 49%, вероятность ошибки намного выше. Легче быть уверенным в крайних ответах, чем в промежуточных.
При определении размера выборки, необходимого для данного уровня точности, вы должны использовать процент наихудшего случая (50%). Вы также должны использовать этот процент, если хотите определить общий уровень точности для уже имеющейся пробы. Чтобы определить доверительный интервал для конкретного ответа, данного вашей выборкой, вы можете использовать процентный выбор этого ответа и получить меньший интервал.
Численность населения
Сколько человек в группе, которую представляет ваша выборка? Это может быть количество людей в городе, который вы изучаете, количество людей, которые покупают новые машины и т. Д.Часто вы можете не знать точную численность населения. Это не является проблемой. Математика вероятности доказывает, что размер популяции не имеет значения, если размер выборки не превышает нескольких процентов от общей популяции, которую вы исследуете. Это означает, что выборка из 500 человек одинаково полезна при изучении мнения государства с населением 15000000 человек и города с населением 100000 человек. По этой причине Survey System игнорирует размер популяции, когда он «большой» или неизвестный. Размер населения может быть фактором, только если вы работаете с относительно небольшой и известной группой людей ( e.грамм. , члены ассоциации).
Расчеты доверительного интервала предполагают, что у вас есть подлинная случайная выборка из соответствующей совокупности. Если ваша выборка не является действительно случайной, вы не можете полагаться на интервалы. Неслучайные выборки обычно возникают в результате каких-либо недостатков или ограничений в процедуре отбора образцов.